Project 1: Predict Real Estate Prices in Beijing
1. Overview
In this project, we will build a linear regression model to help people better understand the factors that can affect the price of a house in Beijing.
The main sections of this article are: (1) Exploratory Data Analysis (EDA), (2) Developing Linear Regression model for predicting real estate price, and (3) Use that model to make predictions.
The Python Notebook containing the complete model development process and the data used in this project can be found at Google Drive.
The model is also deployed on Microsoft Azure Machine Learning Studio, and the documentation could be found here.
2. Exploratory Data Analysis (EDA)
The dataset Google Drive of real estate price in Beijing is from Python Data Science: Technical Details and Business Practices (link). Since the computation was performed on Google Colab platform, we will first mount the Google Drive and load some useful packages.
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import statsmodels.api as sm
# lower case ols means with intercept, upper case OLS means without intercept
from statsmodels.formula.api import ols
import math
import matplotlib
from numpy import corrcoef,array
from IPython.display import HTML, display
pd.set_option('display.max_columns', None)
By copying the dataset from Google Drive to the working directory and load it (see command and results below), we can see that the dataset is composed of 16210 rows and 8 columns.
- District – which district is the house located
- Bedroom – number of bedrooms
- Livingroom – number of living rooms
- Area – area of house in sqft
- Floor – location of house: low floor, mid floor, or high floor
- Subway – whether the house is close to a subway station
- School – whether the house is in a premium school district
- Price – unit price in USD/sqft
These first several columns above represent the independent variables in this dataset, and the last column (i.e., price) is the dependent variable. In the following subsections, we will examine each of them closely.
!cp /content/drive/MyDrive/210-Projects/810_Linear_Regression/sndHsPr_conv.csv ./
sndHsPr = pd.read_csv(r'sndHsPr_conv.csv')
sndHsPr
| district | bedroom | livingroom | area | floor | subway | school | price | |
|---|---|---|---|---|---|---|---|---|
| 0 | chaoyang | 1 | 0 | 496 | middle | 1 | 0 | 623 |
| 1 | chaoyang | 1 | 1 | 636 | middle | 1 | 0 | 593 |
| 2 | haidian | 5 | 2 | 3003 | high | 1 | 1 | 913 |
| 3 | haidian | 3 | 2 | 2228 | high | 1 | 1 | 739 |
| 4 | fengtai | 2 | 1 | 574 | low | 1 | 1 | 908 |
| … | … | … | … | … | … | … | … | … |
| 16205 | chaoyang | 3 | 1 | 822 | middle | 1 | 0 | 668 |
| 16206 | chaoyang | 3 | 1 | 823 | middle | 1 | 0 | 667 |
| 16207 | chaoyang | 2 | 1 | 665 | high | 1 | 0 | 639 |
| 16208 | chaoyang | 1 | 1 | 462 | high | 1 | 0 | 672 |
| 16209 | fengtai | 2 | 1 | 968 | middle | 1 | 0 | 595 |
2.1. Price
As a first step, we will take a close look at the dependent variable, price, which is unit price in US dollar per square feet (USD/sqft).
fig = plt.figure(figsize=(10, 4))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
sns.distplot(sndHsPr.price, fit=stats.norm, bins=40, ax=ax1) # Histogram
ax1.set_xlabel('Unit price (USD/sqft)')
ax1.set_ylabel('Density')
sm.qqplot(sndHsPr.price, fit=True, line='45', ax=ax2)
plt.show()
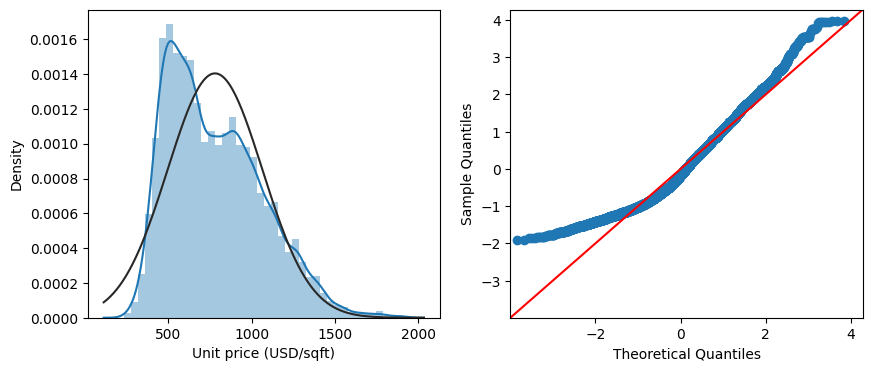
From the Histogram plot and the Q-Q plot above, we notice that the distribution of price is quite different from normal distribution. To alleviate this issue and improve the Normality of the distribution, we will apply log transformation to price by typing sndHsPr['log_price'] = np.log(sndHsPr.price).
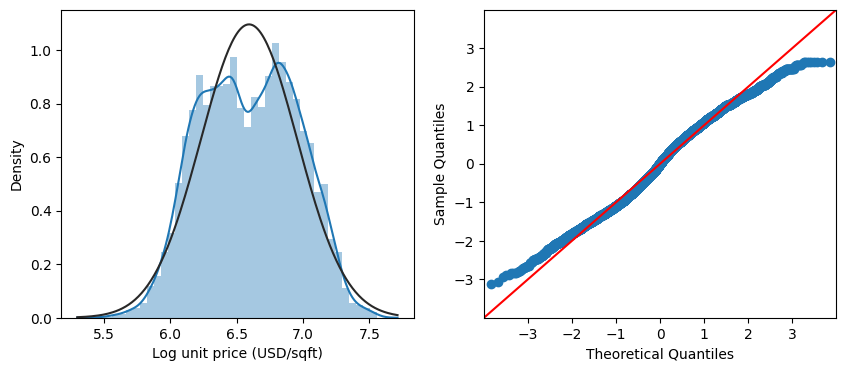
The distribution of log(price) is shown below. Furthermore, if we check the skewness of the distribution by using sndHsPr.price.skew() and sndHsPr.log_price.skew(), we will get 0.679 and -0.012. , So after log transformation, the distribution of price is indeed more close to normal distribution.
2.2. District
Districts of Beijing source
As shown in the picture above, the city of Beijing is composed of Central urban area, Inner suburb area, Outer suburb area, and Remote area. In this study, we will consider 2 districts in the Central urban area (i.e., Dongcheng, Xicheng), as well as 4 districts in the Inner suburb area (i.e., Chaoyang, Haidian, Fengtai, Shijingshan).
fig = plt.figure(figsize=(12, 4))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
sndHsPr.district.value_counts().plot(kind = 'pie',autopct='%.1f%%', ax=ax1)
dat1=sndHsPr[['district','price']]
dat1.district=dat1.district.astype("category")
dat1.district.cat.set_categories(["shijingshan","fengtai","chaoyang","haidian","dongcheng","xicheng"],inplace=True)
sns.boxplot(x='district',y='price',data=dat1, ax=ax2)
plt.ylabel("Unit price (USD/sqft)")
plt.xlabel("District")
plt.title("District vs. unit price")
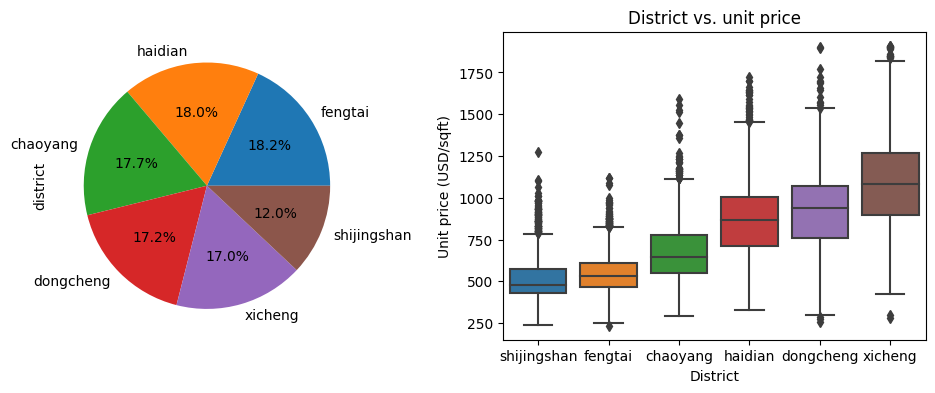
The pie chart and the box plot are generated by the command above. From these plots, we can find that (1) each District is fairly represented in the dataset, there is no undersampling or oversampling issue; and (2) the unit price of real estate in each district is quite different, ranging from ~500 to ~1,100 USD/sqft. So the phrase “Location! Location! Location!” is indeed true.
2.3. Bedroom
Next we will examine the independent variable Bedroom, which means how many bedrooms does the house have. The command used to generate plots are very similar to the command shown above, so I will not show it here and you could find it in the Notebook. From the plots below, we can find that (1) more than 95% of houses are with 1, 2, or 3 bedrooms, it is very rare to find a house with 4 or 5 bedrooms; (2) Unit price of house is quite insensitive to the number of bedrooms.
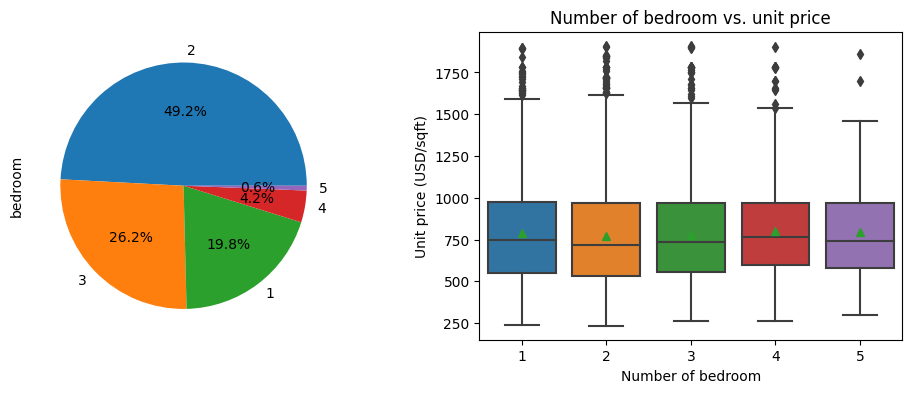
2.4. Living room
The plots below visualize the independent variable Livingroom, which means how many living rooms does the house have. Similar to the plots above, we can see that (1) majority of houses have 1 to 2 living rooms, and that (2) number of living room has minor effect in determining the unit price of a house.
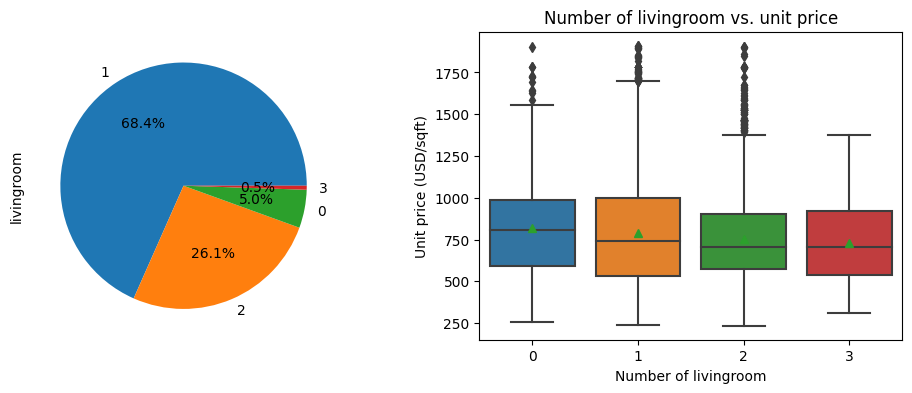
2.5. Floor
Independent variable Floor indicates that whether the house is in low floor, mid floor, or high floor. First of all, it is quite intuitive that each category takes about 1/3 of the dataset. In addition, we also notice that the effects of floor level in determining the unit price of a house is minimal.
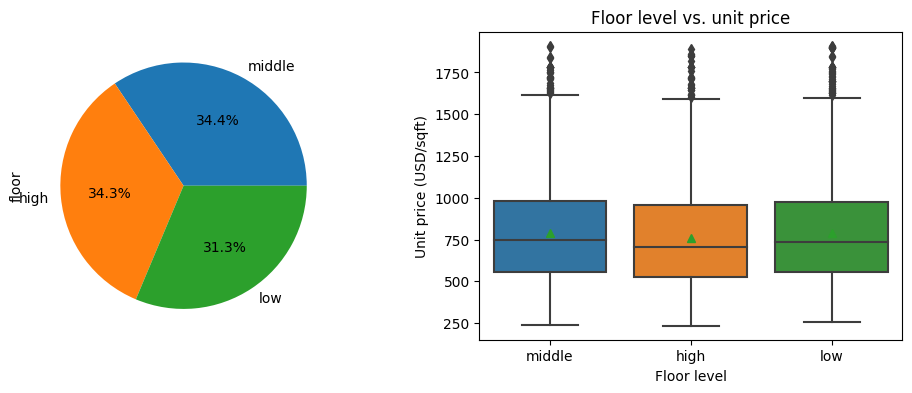
2.6. Subway
Next we will examine the variable Subway, which indicates if the house is close to a subway station (“1” means True and “0” means False). From the plot below, we can see that more than 80% of houses are close to a subway station. This is in good consistency in our expectation, as in this study we only considered the Central urban area and the Inner suburb area. If the Outer suburb area and Remote area were also included in the dataset, I would expect this percentage to be lower.
Also from this plot can we see that Subway is a significant factor in determining the unit price of a house. This is understandable, because living near a subway station can save a lot of time in commuting, especially during rush hours.
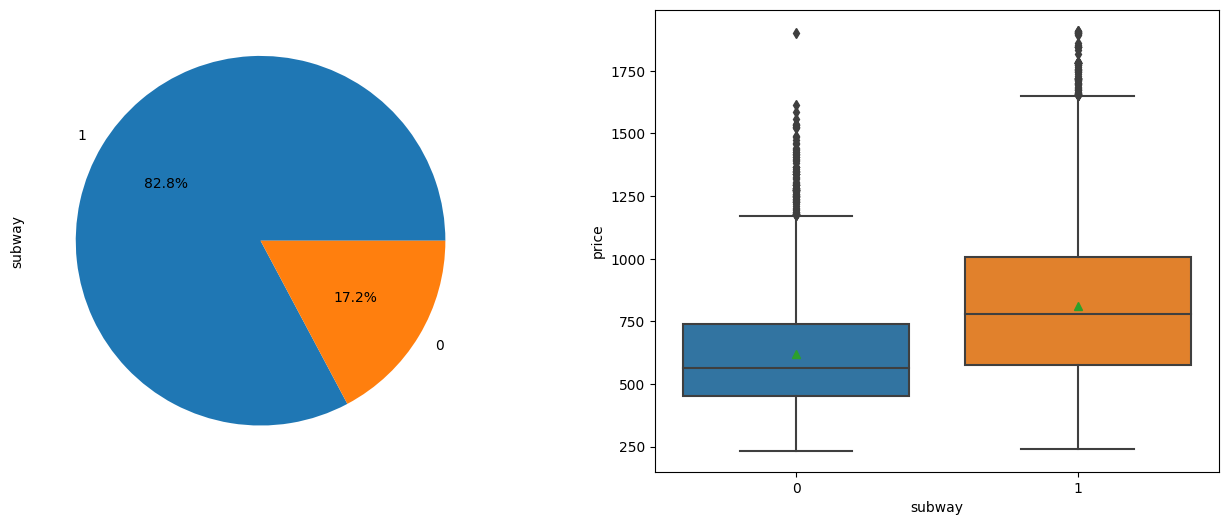
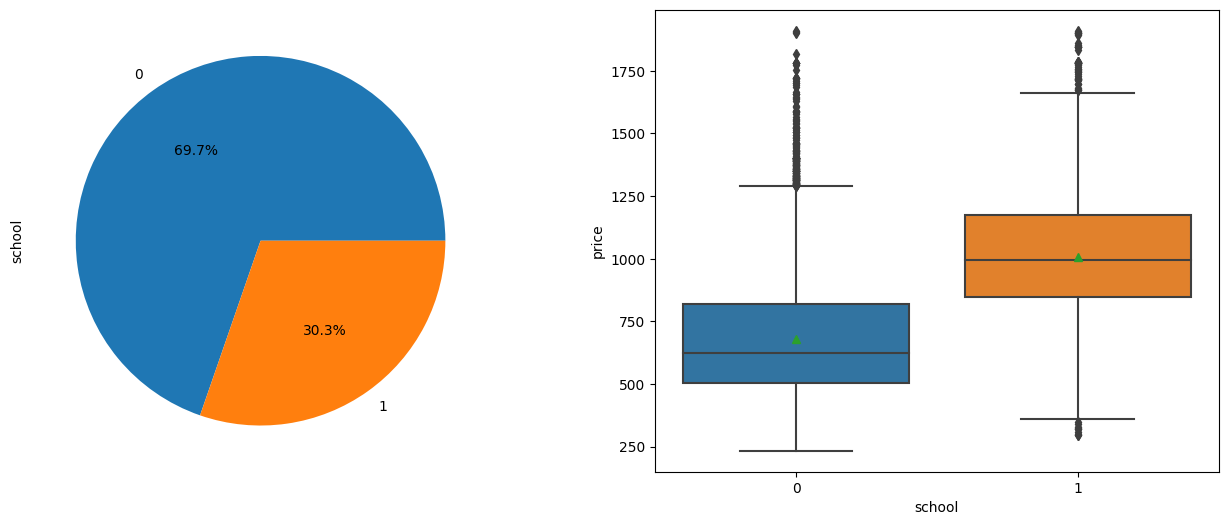
2.7. School
School is an independent variable indicating whether the house is in a premium school district. From the visualization below, we can see that around 70% of houses are in premium school district, and that School plays a significant role in determining the house price.
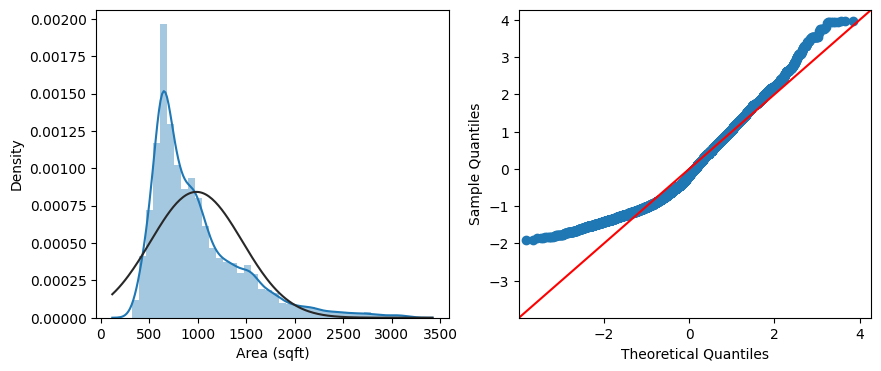
2.8. Area
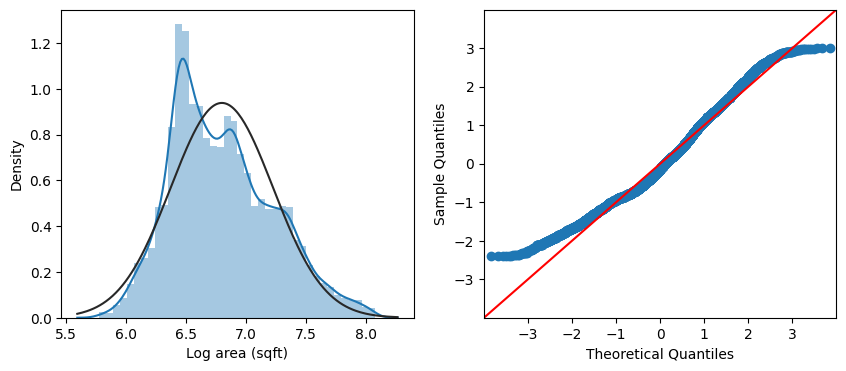
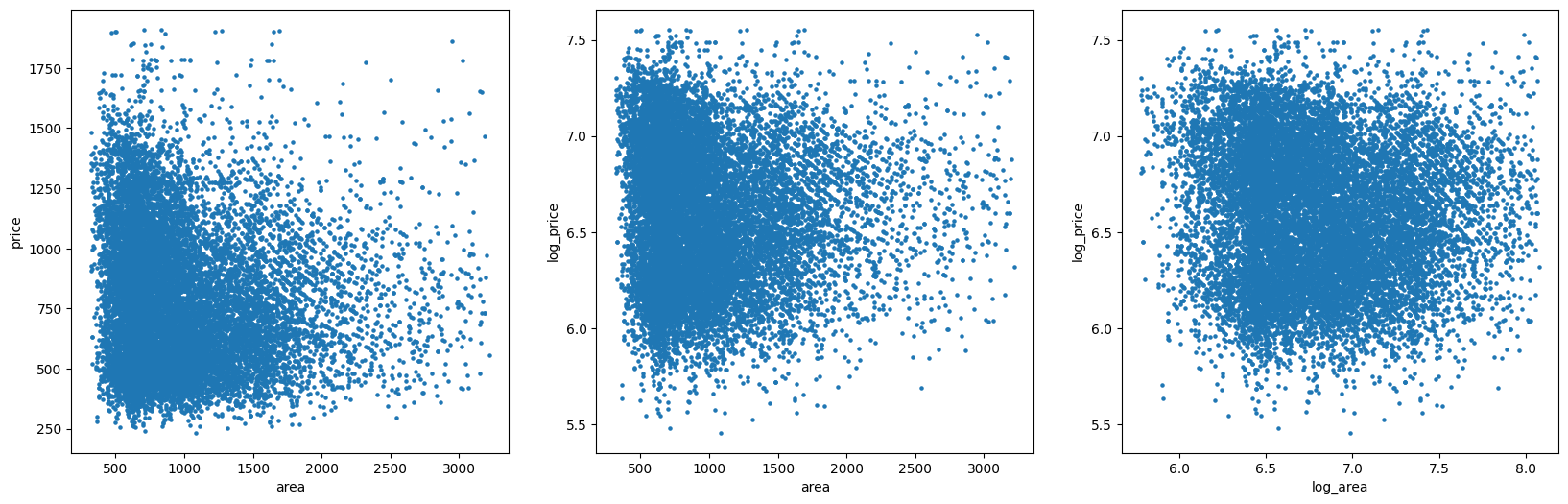
Finally, we will examine the independent variable Area, which is the area of house in square feet (sqft). Similar to the dependent variable Price, we also took log transformation to improve its Normality. This can be observed from the histogram and Q-Q plots below (first row: before log transformation, second row: after log transformation), as well as the scatter plots in the third row.
3. Developing linear regression model
This section is composed of 3 parts. First we will perform subsampling and statistical test for each variable. Then we will build a linear regression model and conduct Regression Diagnostics. Finally we will use the newly built model to make predictions.
3.1. Statistical test
Since the dataset has 16210 samples and is too large for statistical test, we will conduct stratified sampling based on District first, and then we will check the p value for each dependent variable. The code block below shows the subroutine we will employ to conduct subsampling.
def get_sample(df, sampling="simple_random", k=1, stratified_col=None):
"""
Get samples from input dataframe
Inputs:
- df: input dataframe, type: pandas.dataframe
- sampling: sampling method, type: str
Available options: ["simple_random", "stratified", "systematic"]
meaning: Simple random sampling, Stratified sampling, systematic sampling
- k: number of proportion of samples, type: int or float
(int, must > 0; float, must in (0,1) range)
if 0 < k < 1 , then k is the proportion of samples
if k >= 1 , then k is the total number of samples;
or number of samples in each subpopulation (stratum) for Stratified sampling
- stratified_col: list of variables for Stratified sampling
Outputs:
sampling results, type: pandas.dataframe
"""
import random
import pandas as pd
from functools import reduce
import numpy as np
import math
len_df = len(df)
if k <= 0:
raise AssertionError("k can not be negative")
elif k >= 1:
assert isinstance(k, int), "k need to be a positive integer"
sample_by_n = True
if sampling == "stratified":
alln = k * df.groupby(by=stratified_col)[stratified_col[0]].count().count()
# alln=k*df[stratified_col].value_counts().count()
if alln >= len_df:
raise AssertionError("Value of k is too large")
else:
sample_by_n = False
if sampling in ("simple_random", "systematic"):
k = math.ceil(len_df * k)
# print(k)
if sampling == "simple_random":
print("simple random sampling")
idx = random.sample(range(len_df), k)
res_df = df.iloc[idx, :].copy()
return res_df
elif sampling == "systematic":
print("systematic sampling")
step = len_df // k + 1 # step=len_df//k-1
start = 0 # start=0
idx = range(len_df)[start::step] # idx=range(len_df+1)[start::step]
res_df = df.iloc[idx, :].copy()
# print("k=%d,step=%d,idx=%d"%(k,step,len(idx)))
return res_df
elif sampling == "stratified":
assert stratified_col is not None, "please give list of variables for Stratified sampling"
assert all(np.in1d(stratified_col, df.columns)), "please check list of variables for Stratified sampling"
grouped = df.groupby(by=stratified_col)[stratified_col[0]].count()
if sample_by_n == True:
group_k = grouped.map(lambda x: k)
else:
group_k = grouped.map(lambda x: math.ceil(x * k))
res_df = df.head(0)
for df_idx in group_k.index:
df1 = df
if len(stratified_col) == 1:
df1 = df1[df1[stratified_col[0]] == df_idx]
else:
for i in range(len(df_idx)):
df1 = df1[df1[stratified_col[i]] == df_idx[i]]
idx = random.sample(range(len(df1)), group_k[df_idx])
group_df = df1.iloc[idx, :].copy()
res_df = res_df.append(group_df)
return res_df
else:
raise AssertionError("sampling is illegal")
We use this code to conduct stratified sampling based on District (400 samples for each District, 2400 observations in total). Then we computed the p value of each variable, and the results are shown in the table below. From this result, we can see that variables such as Bedroom, Living room, and Floor have a high p value, so we will not include them in the model.
sndHsPr_400 = get_sample(sndHsPr, sampling="stratified", k=400, stratified_col=['district'])
print("p value of District: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(district)', data=sndHsPr_400).fit())._values[0][4])
print("p value of Bedroom: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(bedroom)', data=sndHsPr_400).fit())._values[0][4])
print("p value of Livingroom: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(livingroom)', data=sndHsPr_400).fit())._values[0][4])
print("p value of Floor: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(floor)', data=sndHsPr_400).fit())._values[0][4])
print("p value of Subway: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(subway)', data=sndHsPr_400).fit())._values[0][4])
print("p value of School: \t%.4f" % sm.stats.anova_lm(ols('price ~ C(school)', data=sndHsPr_400).fit())._values[0][4])
print("p value of Area: \t%.4f" % sm.stats.anova_lm(ols('price ~ area', data=sndHsPr_400).fit())._values[0][4])
| Variable | p value |
|---|---|
| District | 0.0000 |
| Bedroom | 0.2601 |
| Livingroom | 0.3774 |
| Floor | 0.1719 |
| Subway | 0.0000 |
| School | 0.0000 |
| Area | 0.0047 |
3.2. Model development
With the help of statsmodels package, we can build and diagnose the linear regression model by using the command block below conveniently.
lm1 = ols("price ~ C(district)+C(subway)+C(school)+area", data=sndHsPr_400).fit()
lm1_summary = lm1.summary()
lm1_summary
sndHsPr_400['pred1']=lm1.predict(sndHsPr_400)
sndHsPr_400['resid1']=lm1.resid
sndHsPr_400.plot('pred1','resid1',kind='scatter')
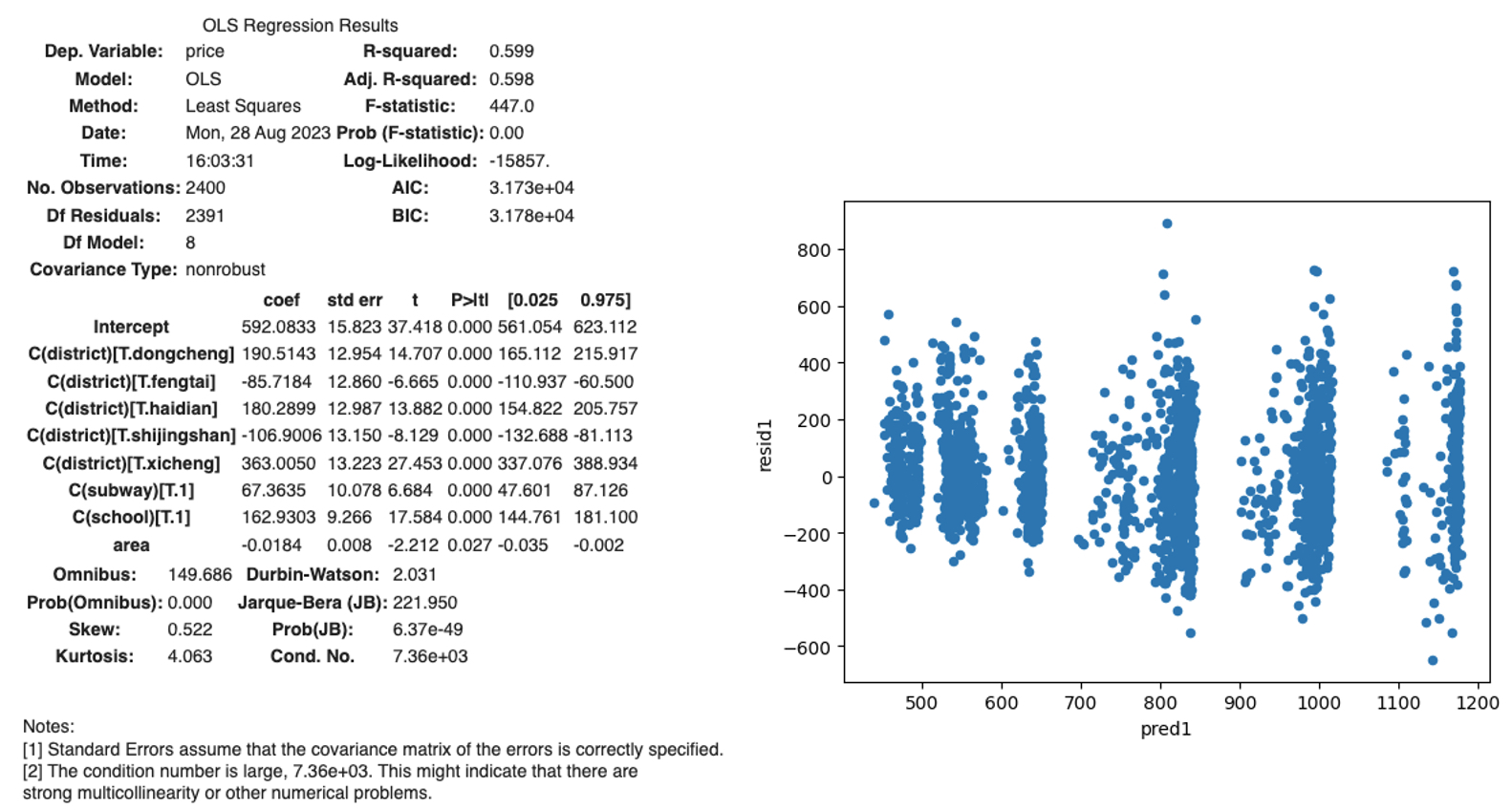
From the results above, we can see that the adjusted r^2 = 0.598, which is quite decent for real world problems. On the other hand, we also observed heteroscedasticity in the scatter plot of the residual, which is in consistency with the distribution of dependent variable Price we examined in Section 2.1.
To address this critical issue, we will use log_price and log_area to replace price and area and refit the model. From the results below, we can see that most important of all, heteroscedasticity is eliminated. Also, adjusted r^2 is slighted improved from 0.598 to 0.608 as well.
lm2 = ols("log_price ~ C(district)+C(subway)+C(school)+log_area", data=sndHsPr_400).fit()
lm2_summary = lm2.summary()
lm2_summary
sndHsPr_400['pred2']=lm2.predict(sndHsPr_400)
sndHsPr_400['resid2']=lm2.resid
sndHsPr_400.plot('pred2','resid2',kind='scatter')
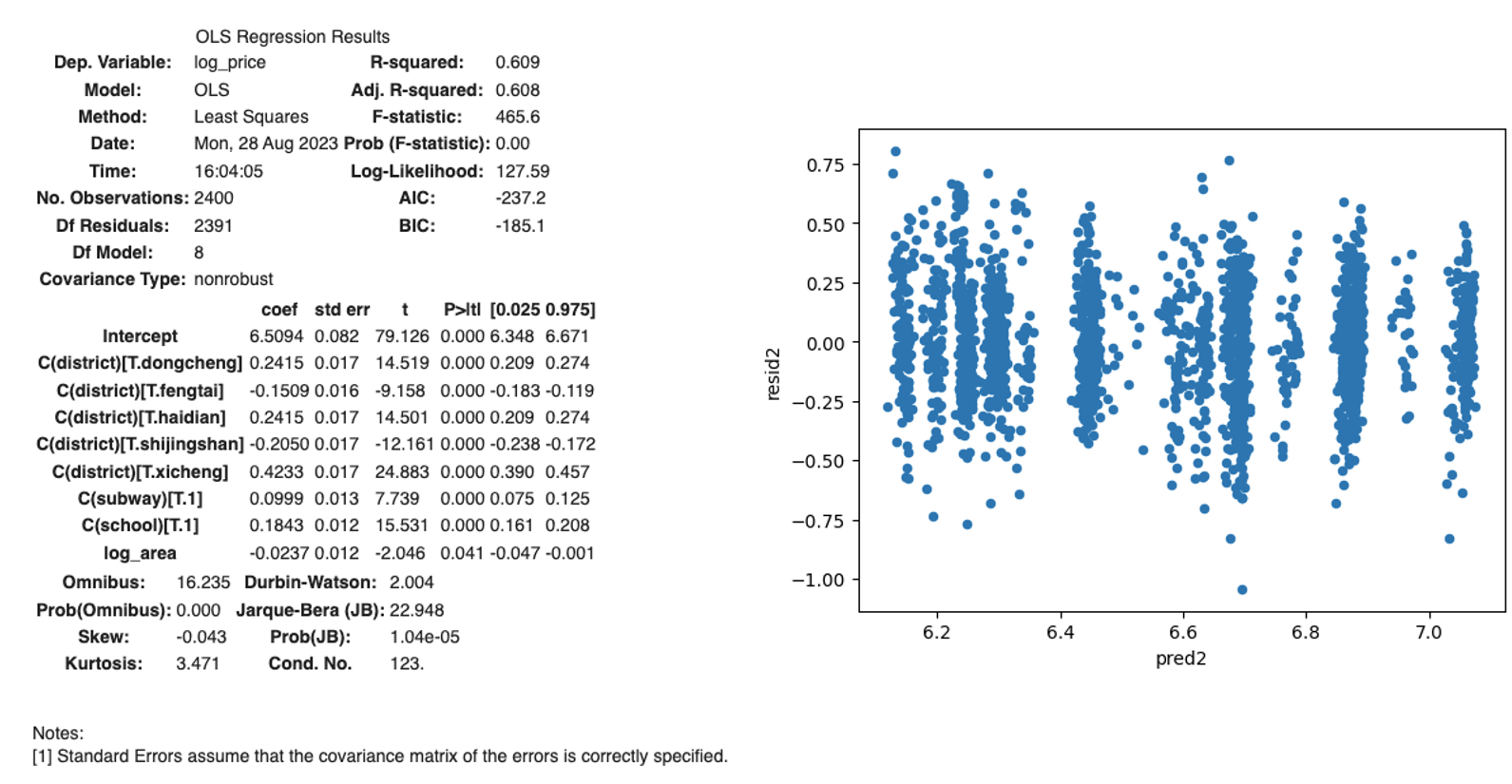
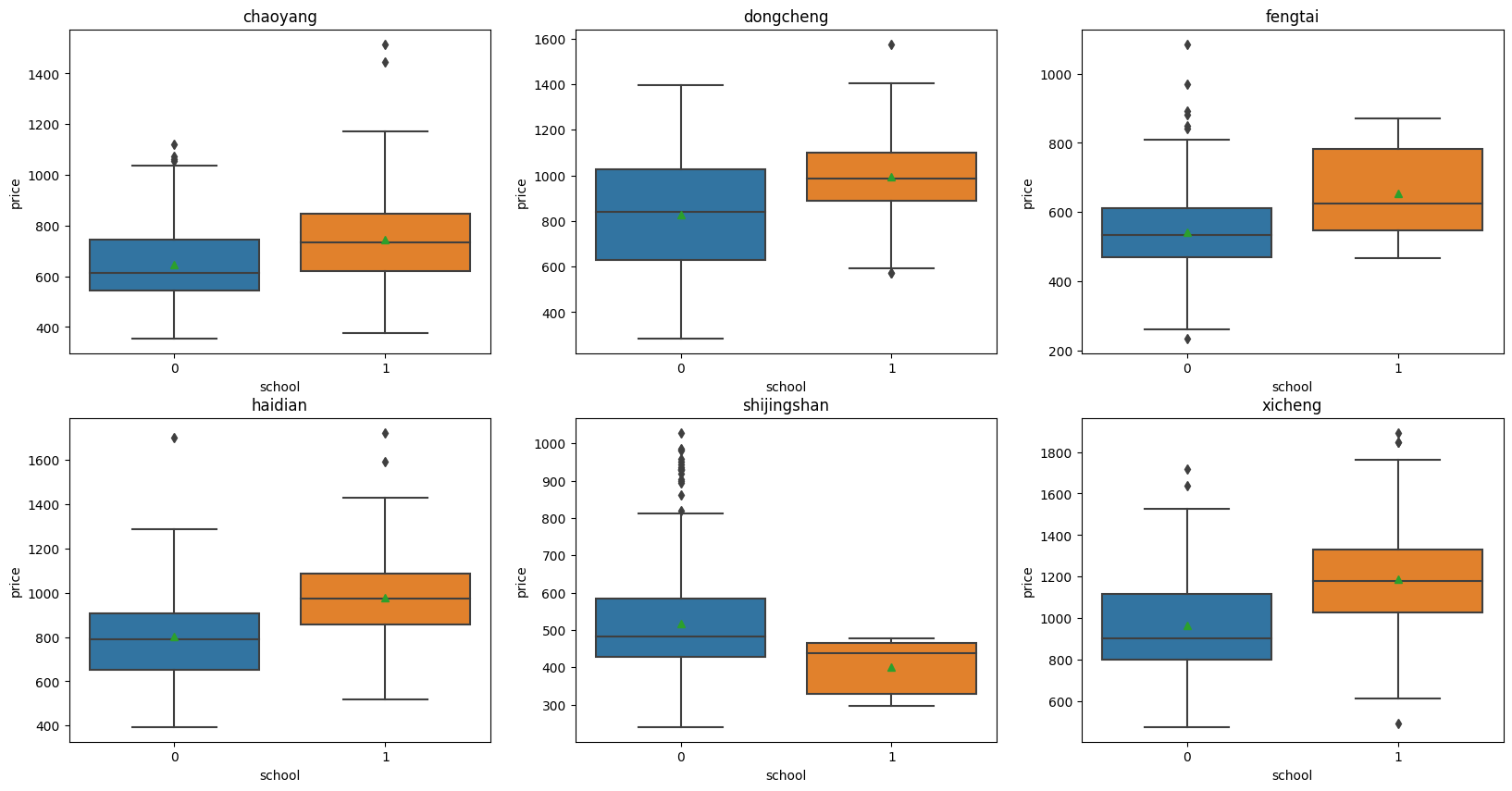
Finally, we would like to investigate the interaction effects of District and School. From the box plot below, we can see that in Shijingshan district, price of a house in premium school district is lower than those not in premium school district. This is counterintuitive, and it is also inconsistent with other districts. Further investigation found that samples in Shijingshan district are highly unbalanced and only 5 out of 400 of samples (1.25%) are in premium school district.
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(2,3,1)
ax2 = fig.add_subplot(2,3,2)
ax3 = fig.add_subplot(2,3,3)
ax4 = fig.add_subplot(2,3,4)
ax5 = fig.add_subplot(2,3,5)
ax6 = fig.add_subplot(2,3,6)
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='chaoyang'], showmeans=True, ax=ax1).set_title("chaoyang")
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='dongcheng'], showmeans=True, ax=ax2).set_title("dongcheng")
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='fengtai'], showmeans=True, ax=ax3).set_title("fengtai")
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='haidian'], showmeans=True, ax=ax4).set_title("haidian")
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='shijingshan'], showmeans=True, ax=ax5).set_title("shijingshan")
sns.boxplot(x='school', y='price', data = sndHsPr_400[sndHsPr_400.district=='xicheng'], showmeans=True, ax=ax6).set_title("xicheng")
###Check unusual price trend in shijingshan district -- probably samlpe size is too small and not representative
print('shijingshan - premium school district: \t',sndHsPr_400[(sndHsPr_400['district']=='shijingshan')&(sndHsPr_400['school']==1)].shape[0])
print('shijingshan - Not premium school district: \t',sndHsPr_400[(sndHsPr_400['district']=='shijingshan')&(sndHsPr_400['school']==0)].shape[0])
print('only 5 out of 400 of houses (1.25%) in shijingshan are in premium school district')
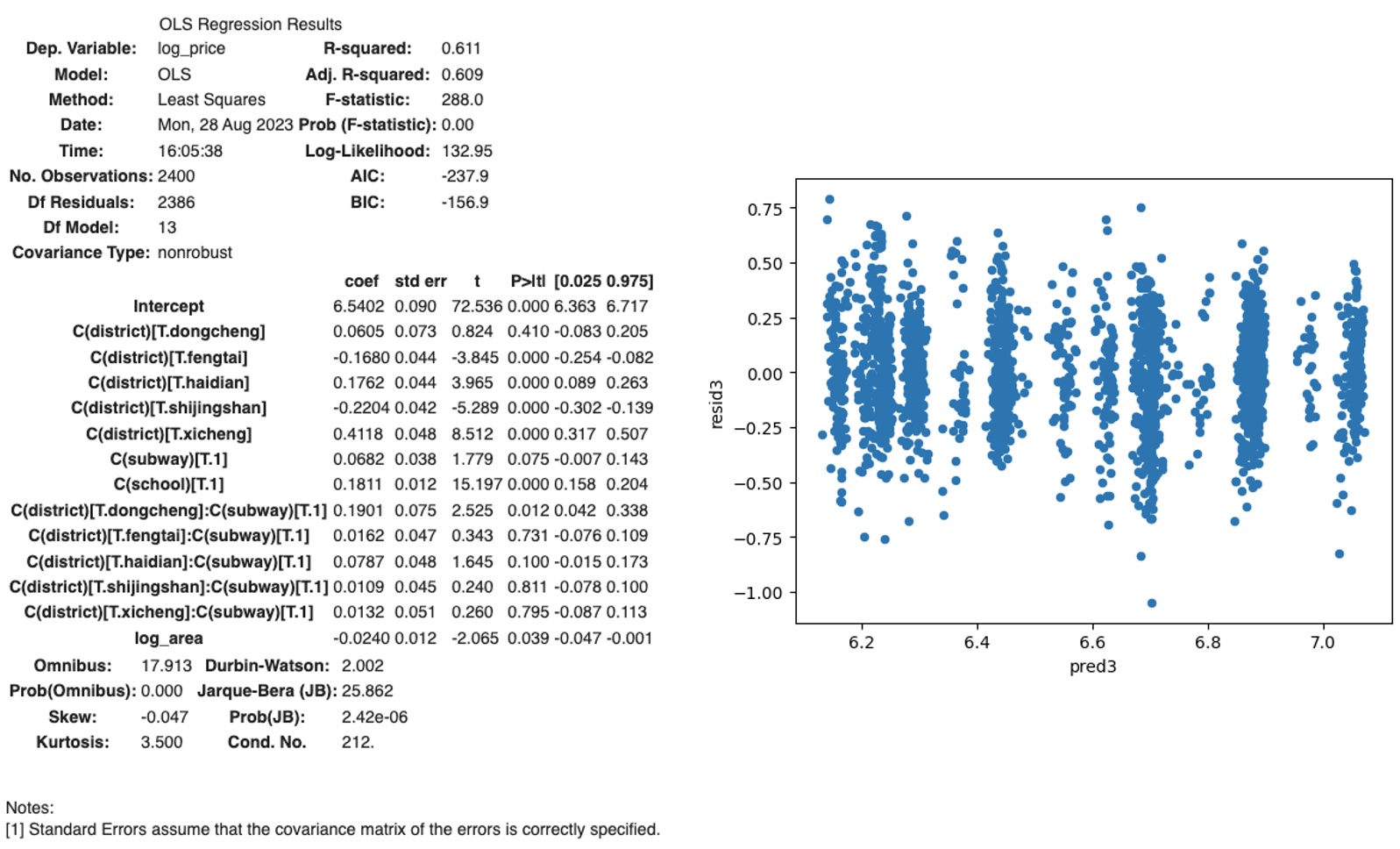
In the code block below, we further improve the model by taking into consideration the interaction effects of District and School. There is minor improvement of adjusted r^2 from 0.608 to 0.609, and the heteroscedasticity is also eliminated in the scatter plot of residuals.
lm3 = ols("log_price ~ C(district)*C(subway)+C(school)+log_area", data=sndHsPr_400).fit()
lm3_summary = lm3.summary()
lm3_summary
sndHsPr_400['pred3']=lm3.predict(sndHsPr_400)
sndHsPr_400['resid3']=lm3.resid
sndHsPr_400.plot('pred3','resid3',kind='scatter')
3.3. Model prediction
Question: Assuming a family is interested in buying a 2 bedroom, 1 livingroom house in Dongcheng district, which is 700 sqft, in mid floor, close to subway station, and in premium school district. How much should they expect to pay?
# district bedroom livingroom area floor subway school
# dongcheng 2 1 700 1 1 1
X_test = [['dongcheng', 1, 1, np.log(700)]]
X_test = pd.DataFrame(X_test, columns = ['district', 'school', 'subway', 'log_area'])
unit_price_pred = np.exp(lm3.predict(X_test))
total_price_pred = unit_price_pred * 700
print("predicted unit price: ", round(unit_price_pred[0], 1), "USD/sqft")
print("predicted total price: ", round(total_price_pred[0], 1), "USD")
To answer this question, let’s predict the unit price of this house using our newly developed model. Our model shows that the unit price of such a house is $975.6 per sqft, and the total price they need to pay is $682,915.
4. Conclusion and future work
In this project, I have developed a linear regression model to predict the house price in Beijing, based on its District, whether it is close to subway station, whether it is in preminum school district, and its area. The model can explain about 61% of variations in price, which is quite decent given the limitation of linearity and the scattered nature of the dataset. If explainability is not required legally or ethically, researchers can also consider using artificial neural network or ensemble method such as Gradient-boosted decision trees. These models usually can give better results.