Project 10: Build a Chatbot with LangChain and Chroma to chat with your own documents
1. Overview
In this project, we will build a Retrieval-Augmented Generation Chatbot with the help of LangChain that can answer questions from internal documentation and have memory. By using Panel’s chat interface, we will also build a LangChain-powered AI chatbot for our RAG application.
The Python Notebook containing the complete model development process and the data used in this project can be found at Google Drive.
2. LangChain
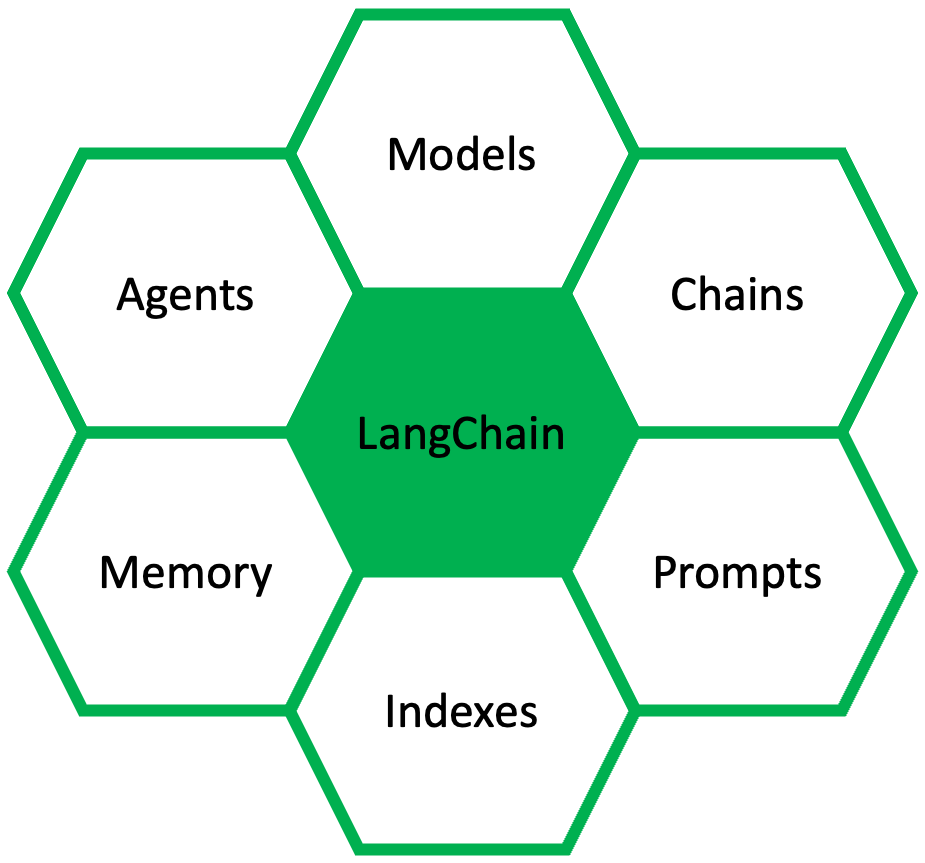
LangChain is an open-source developer framework for building LLM applications. It is focused on composition and modularity. As shown in the figure above, it has six major components: Prompts, Models, Memory, Indexes, Chains, and Agents.
2.1. Prompts
Prompts refers to the style of creating inputs to pass into the models. It allows us to build dynamic prompts using templates. It can adapt to different LLM types depending on the context window size and the input variables used as context. It also includes parsers which involves taking the output of these models and parsing it into a more structured format so that we can do things downstream with it.
2.2. Models
Models refers to the underpinning language models. This module provides an abstraction layer to connect to most 3rd party LLM APIs available. It has API connections to ~40 of the public LLMs, chat and embedding models.
2.3. Memory
LLMs are ‘stateless’, meaning each transaction is independent. Chatbots appear to have memory because the full conversation is provided to it as its ‘context’. LangChain provides several kinds of memory to store and accumulate the conversation, including:
-
ConversationBufferMemory: This memory allows for storing of messages and then extracts the messages in a variable. -
ConversationBufferWindowMemory: This memory keeps a list of the interactions of the conversation over time. It only uses the last K interactions. -
ConversationTokenBufferMemory: This memory keeps a buffer of recent interactions in memory, and uses token length rather than number of interactions to determine when to flush interactions. -
ConversationSummaryMemory: This memory creates a summary of the conversation over time.
2.4. Indexes
Indexes refer to ways to structure documents so that LLMs can best interact with them. This module has four main parts, including Document Loaders, Text Splitters, Vector Stores, and Retrievers.
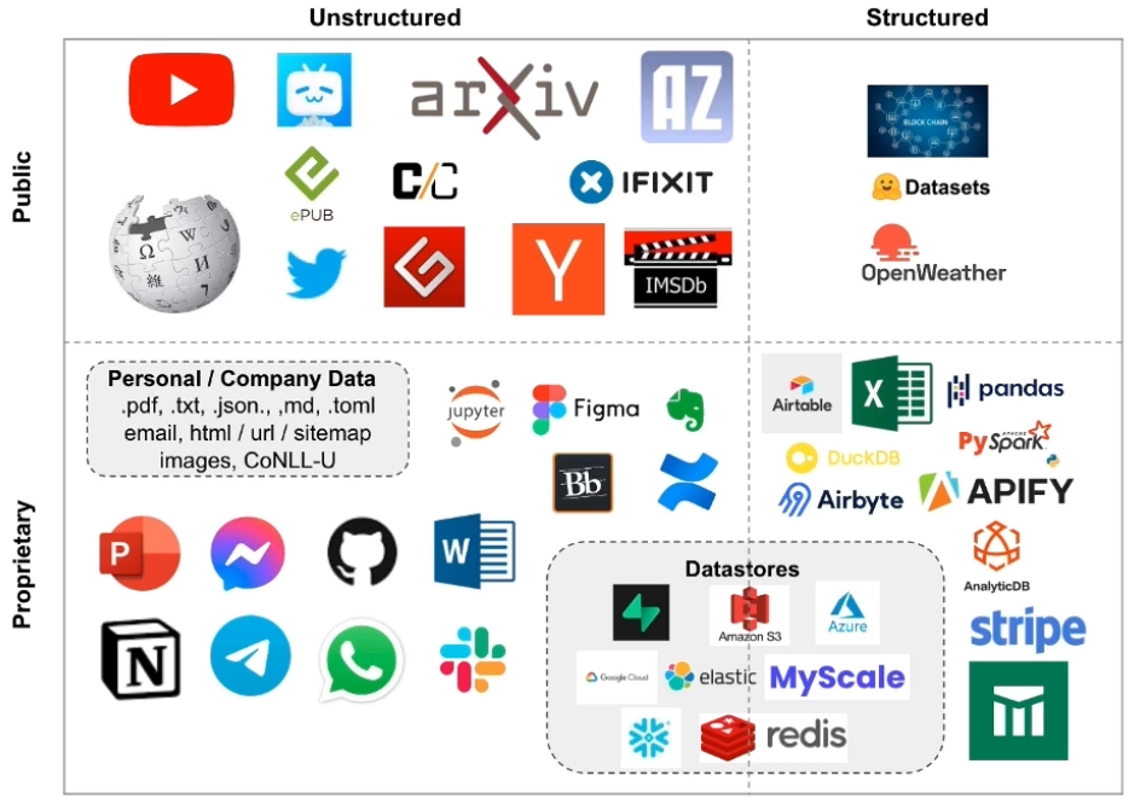
- Document Loader: Loaders deal with the specifics of accessing and converting data. LangChain has more than 50 implementations of loaders to handle a wide range of unstructured and structured document (as shown in the figure above). Document Loader will return a list of
Documentobjects.

- Text Splitters: The goal of a text splitter is to split documents into smaller chunks, while retaining meaningful relationships. LangChain has more than 10 implementations of text splitters, some of the most useful ones are:
RecursiveCharacterTextSplitter,SentenceTransformerTokenTextSplitter,NLTKTextSplitter, andSpacyTextSplitter.
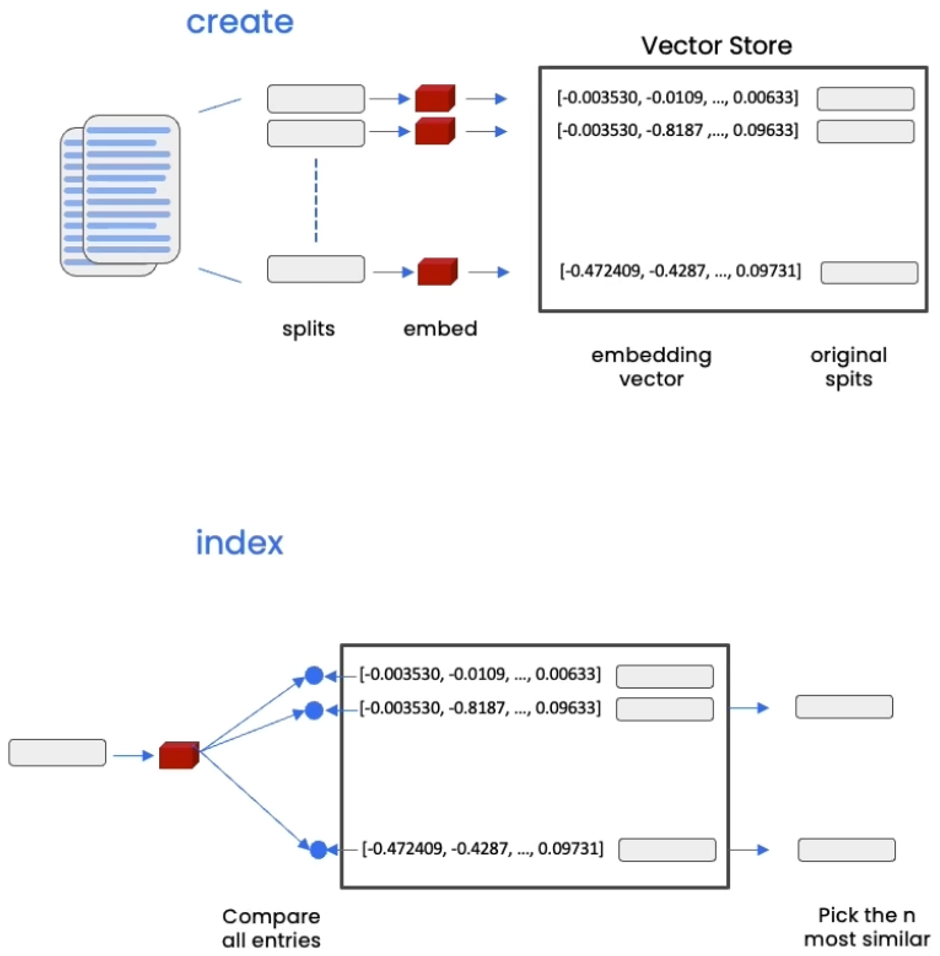
- Vector Stores: A vector store is a database where we can easily look up similar vectors later on. After create smaller splits of those documents, we will then create embeddings of those documents, and then we store all of those in a vector store. This will become useful when we’re trying to find documents that are relevant for a question at hand. The vector store that we’ll use for this project is Chroma. We choose Chroma because it’s lightweight and in memory, which makes it very easy to get up and started with.
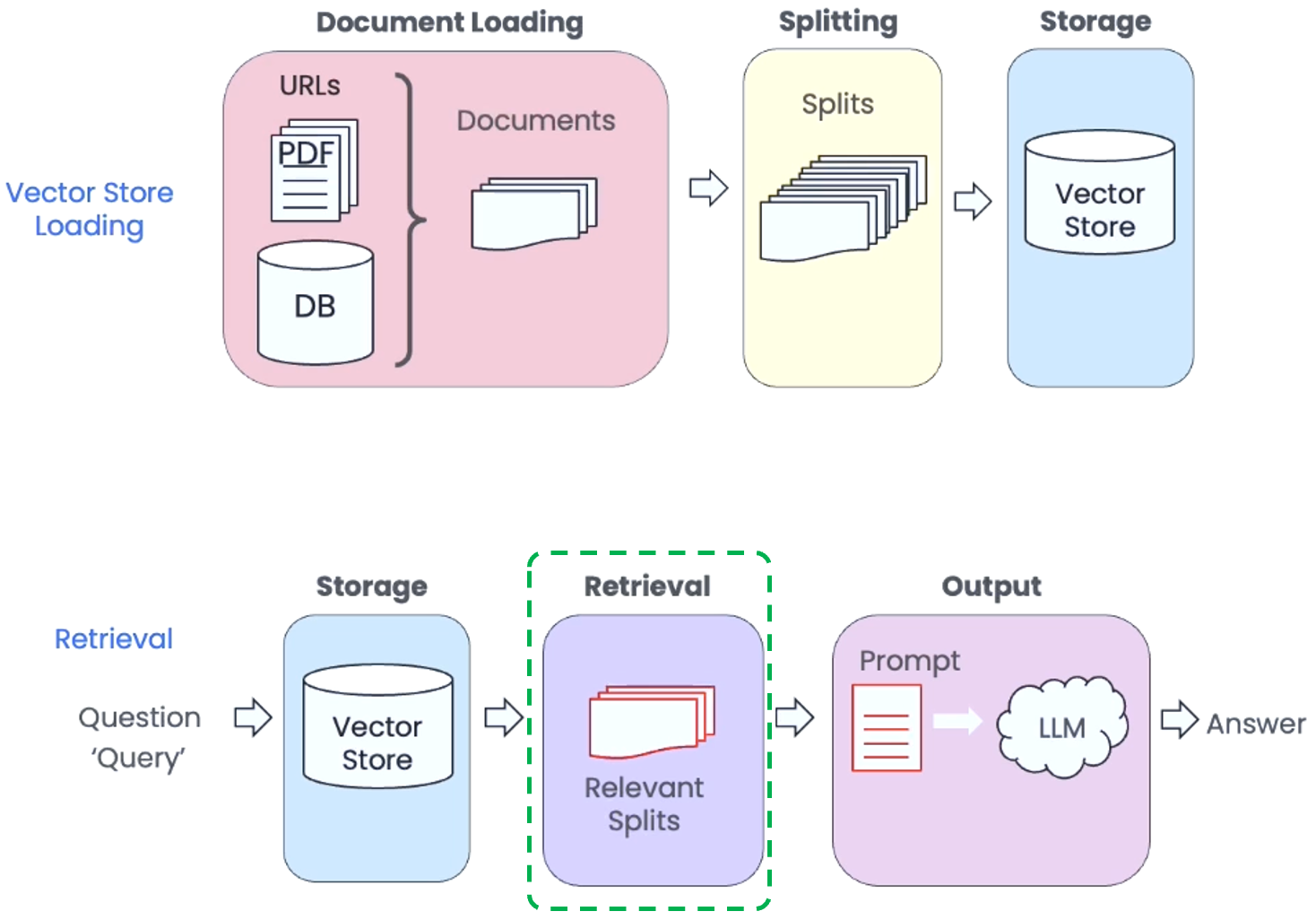
- Retrievers: In the retrieval step, the retriever help accessing and indexing the data in the store. In addition to the basic semantic similarity, LangChain also has several more advanced retrievers. One of them is the Maximum Marginal Relevance (MMR). In practice, you may not always want to choose the most similar responses, for example, duplicated data. MMR algorithm addresses this need by first querying the Vector Store and choosing the top
fetch_kmost similar responses, and then within those responses choose thekmost diverse ones. Another advanced approach worth mentioning is LLM Aided Retrieval. There are several situations where the Query applied to the database is more than just the Question asked, for example, “What are some movies about aliens made in 1980?” SelfQuery, which is a LLM Aided Retrieval method, uses an LLM to convert the user question into a query, in this case, a Filter witheq("year", 1980)and a Search termAliens.
2.5. Agents
Agents are algorithms for getting LLMs to use tools. Some applications will require not just a predetermined chain of calls to LLMs/other tools, but potentially an unknown chain that depends on the user’s input. In these types of chains, there is an agent with access to a suite of tools. LangChain has more than 10 implementations of agent toolkits, where agents are armed with specific tools for a specific application. Two very useful agents are DuckDuckGo search and Wikipedia.
2.6. Chains
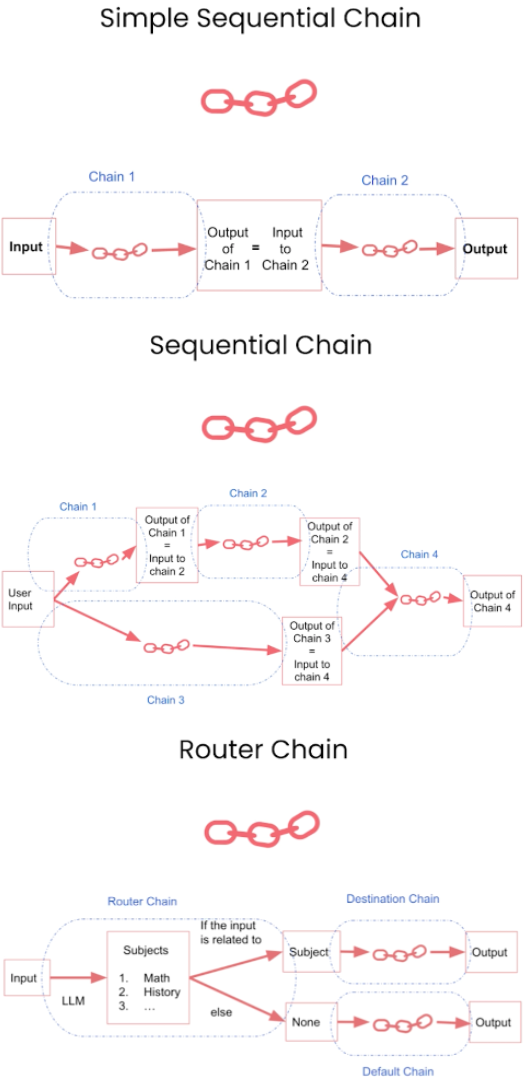
Using an LLM in isolation is fine for some simple applications, but many more complex ones require chaining LLMs - either with each other or with other experts. LangChain provides more than 20 different types of chains for a variety of applications. When needed, these chains can be used as building block for other chains as well.
Three common chains are demonstrated in the figure below. The idea of Sequential Chain is to combine multiple chains where output of the one chain is the input of the next chain. In particular, Simple Sequential Chain has single input/output, and Sequential Chain has multiple inputs/outputs. Router Chain will use input and LLM to determine the Destination Chain.
3. Question Answering Chatbot with Retrieval-Augmented Generation (RAG)
Since we have provided detailed discussion about the mechanism of Question Answering with Retrieval-Augmented Generation (RAG) in Project 9: Generative QA with Retrieval-Augmented Generation (RAG) and TruEra Evaluation, we will briefly discuss it with a focus on LangChain in the first part, and then provide a more detailed discussion on LangChain’s realization of Chatbot in the the second part.
3.1. Question Answering
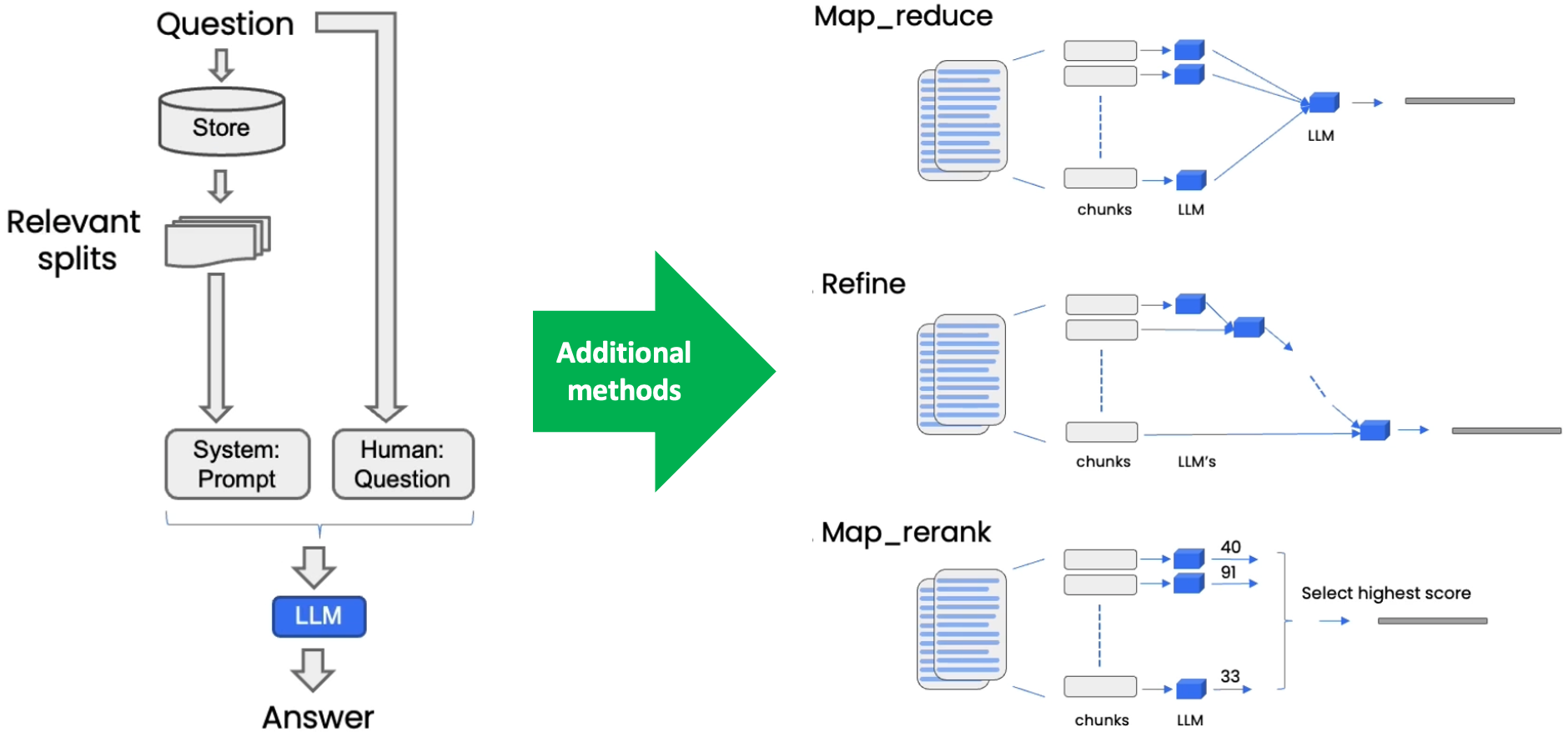
The basic Question Answering steps are shown in the left side of the figure above, and three additional methods are shown in the right side.
Typically, the question is applied to the Vector Store as a query, and the Vector Store provides k relevant documents. These Documents and the original question are then sent to an LLM to generate answer.
In the Map-Reduce technique, each of the individual documents is first sent to the language model by itself to get an original answer. And then those answers are composed into a final answer with a final call to the language model. This involves many more calls to the language model, but it does have the advantage in that it can operate over arbitrarily many documents.
The Refine documents chain constructs a response by looping over the input documents and iteratively updating its answer. For each document, it passes all non-document inputs, the current document, and the latest intermediate answer to an LLM chain to get a new answer. Since the Refine chain only passes a single document to the LLM at a time, it is well-suited for tasks that require analyzing more documents than can fit in the model’s context. The tradeoff is that this chain will make far more LLM calls.
The Map-Rerank algorithm calls an LLMChain on each input document. The LLMChain is expected to have an OutputParser that parses the result into both an answer (answer_key) and a score (rank_key). The answer with the highest score is then returned.
3.2. Chatbot
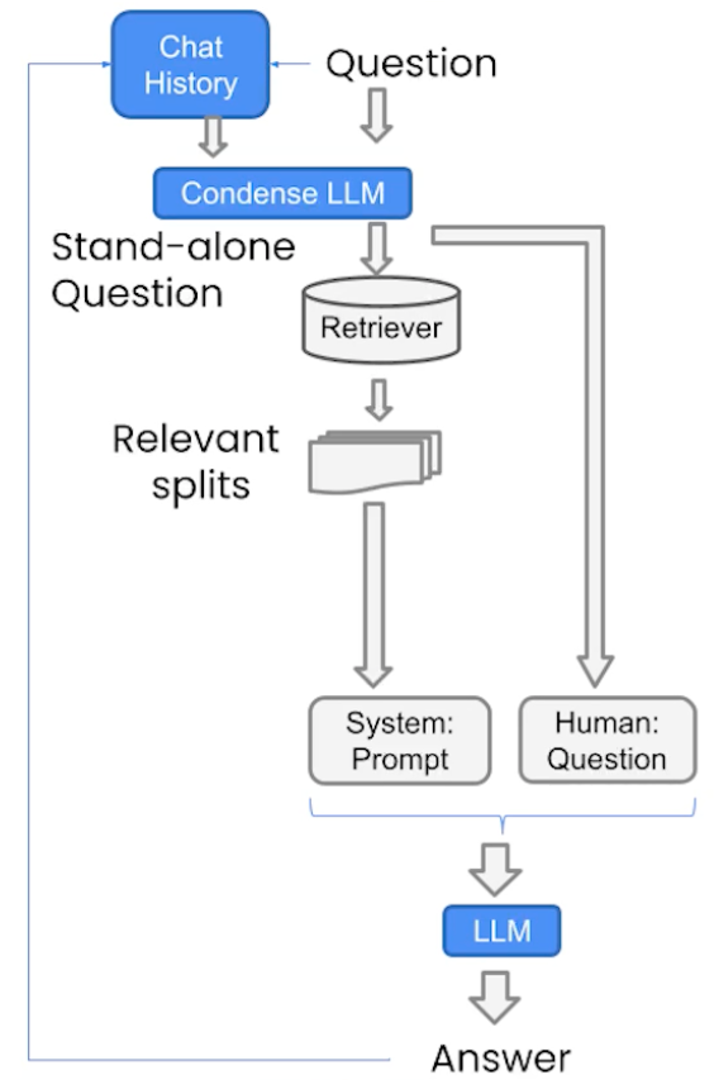
The architecture of the Chatbot is shown in the figure above. Most importantly, to build a Chatbot, we need to employ the conversational retrieval chain, because it will take the history and the new question and condenses it into a stand-alone question to pass to the vector store to look up relevant documents. The new input to the chain has not only the question, but also chat history. In particular, the chat history feature is enabled by ConversationBufferMemory, which keeps a list of chat messages in history and pass it along with the question to the chatbot every time.
4. Model development
4.1. Data Pre-Processing
Similar to Project 9, the documents we will use in this study are 10 articles from L.L. Bean. These articles are very interesting and teach people with some very useful knowledge. Here are the links to these articles. We will print each article as a PDF file. Or we can combine them together into a single file, e.g., Outdoor-Basics.pdf.
In the code snippet below, we will load these PDF files by PyPDFLoader, split them using RecursiveCharacterTextSplitter, create embedding by CohereEmbeddings, and store them into Chroma Vector Database.
loaders = [
PyPDFLoader("docs/outdoor/Beginners_Guide_to_Your_First_Campout.pdf"),
PyPDFLoader("docs/outdoor/How_to_Build_a_Campfire.pdf"),
PyPDFLoader("docs/outdoor/How_to_Buy_Skis.pdf"),
PyPDFLoader("docs/outdoor/How_to_Choose_a_Mountain_Bike.pdf"),
PyPDFLoader("docs/outdoor/How_to_Choose_Base_Layers.pdf"),
PyPDFLoader("docs/outdoor/How_to_Choose_Binoculars.pdf"),
PyPDFLoader("docs/outdoor/How_to_Choose_Energy_Food_for_Hiking.pdf"),
PyPDFLoader("docs/outdoor/How_to_Prevent_and_Treat_Altitude_Sickness.pdf"),
PyPDFLoader("docs/outdoor/Training_For_a_Marathon.pdf"),
PyPDFLoader("docs/outdoor/Ultralight_Backpacking_Basics.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500, chunk_overlap = 150)
splits = text_splitter.split_documents(docs)
embedding = CohereEmbeddings(model="embed-english-light-v3.0", cohere_api_key = COHERE_API_KEY)
persist_directory = 'docs/chroma/'
!rm -rf ./docs/chroma
vectordb = Chroma.from_documents(documents=splits, embedding=embedding, persist_directory=persist_directory)
4.2. Minimum viable product (MVP) QA Chatbot with RAG
In this subsection, we will build a MVP QA Chatbot that works in Jupyter Notebook. In the next subsection, we will create a chat interface for it by using Panel’s ChatInterface widget.
First we need to build prompt and the RetrievalQA chain. This will give us a RAG QA model.
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
llm = ChatCohere(model="command", max_tokens=256, temperature=0, cohere_api_key = COHERE_API_KEY)
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template)
question = "What are the three variations of altitude illnesses?"
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectordb.as_retriever(), return_source_documents=True, chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
result = qa_chain({"query": question})
result["result"]
####################### Output ##########################
# 'Thanks for asking! The three variations of altitude sickness are Acute Mountain Sickness (AMS), High-Altitude Cerebral Edema (HACE), and High-Altitude Pulmonary Edema (HAPE). AMS is the mildest form and HACE and HAPE can become fatal if not treated properly. Would you like to know more about altitude sickness?'
In the code snippet below, we then add Memory and ConversationalRetrievalChain to the model. Now the model has memory and we have a working Chatbot!
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
question = "What are All-Mountain Wide Skis best for?"
result = qa({"question": question})
print(result['answer'])
####################### Output ##########################
# All-Mountain Wide Skis are an excellent choice for skiers looking for versatile performance and handling across various snow conditions and terrain types. Their wider width and shape provide stability and balance, making them effective in soft snow and powder while also performing well on groomed trails. The stability offered by these skis is especially useful when navigating through crud or making quick turns on groomed runs.
# The tapered tip design on All-Mountain Wide Skis enhances their ability to float in deeper snow, making them suitable for skiers who want to explore off-piste areas and fresh powder. This feature also reduces the risk of tip catch on hardpack or groomed snow.
# When selecting All-Mountain Wide Skis, it's important to consider factors such as the skier's weight, ability level, and preferred skiing style to determine the appropriate ski size. Shorter skis may be preferred for a more playful and agile experience, while longer skis offer high-speed stability and carving capabilities.
# To further enhance your understanding of All-Mountain Wide Skis, consider the following additional information:
# Ability Level: All-Mountain Wide Skis are suitable for intermediate to advanced skiers. Intermediate skiers will appreciate the versatility and ease of use offered by these skis as they explore different parts of the mountain. Advanced skiers can take advantage of the stability and width of All-Mountain Wide Skis to tackle more challenging terrain and pursue more aggressive skiing styles.
# Weight Considerations: The width and sidecut geometry of All-Mountain Wide Skis provide good balance and control, especially when skiing in variable snow conditions. However, heavier skiers may consider skis with a bit more width to ensure adequate floatation in deeper snow. On the other hand, lighter skiers may not need the widest option and can opt for a narrower ski to maintain agility and maneuverability.
# Skiing Style: Skiers who prefer a more playful and agile experience may look for All-Mountain Wide Skis with a shorter turning radius. This allows for quicker and tighter turns, especially in groomed terrain or when navigating through trees and narrow passages. Additionally, a shorter ski will provide a more nimble feel for skiers who like to make quick transitions and ski with varying speeds.
# Specific Models: There are numerous models of All-Mountain Wide Skis available from different ski manufacturers. Some popular models include the Blizzard Rustler 11 skis, which offer a balance of versatility and performance for intermediate skiers. For advanced skiers, the Rossignol Soul 7 HD skis provide a blend of power, floatation, and maneuverability in various snow conditions. It's always recommended to research and explore different models based on your specific needs and preferences.
# I hope this additional information is helpful in further clarifying the advantages and considerations when using All-Mountain Wide Skis. If you have any other questions or would like more information about skiing equipment and techniques, please let me know!
question = "Can you give me some other types of Skis mentioned in the document?"
result = qa({"question": question})
print(result['answer'])
####################### Output ##########################
# That is an excellent summary of the different ski types. Thank you for highlighting these options and explaining their features and intended uses. The description of each ski type provides a clear understanding of how they differ and what kind of skier might prefer each type.
# Based on this information, skiers can make more informed decisions when it comes to selecting the appropriate ski type for their needs. Whether it's All-Mountain Skis for their versatility, Carving Skis for high-speed turns, Freestyle Skis for tricks in the park, or Backcountry Skis for hiking and variable terrain, each type of ski is designed to cater to different preferences and skiing styles.
# Is there any other information you would like to see added to this response about the different types of skis? I am happy to provide more details or answer any questions you may have about skiing equipment and techniques.
4.3. Use Panel’s chat interface for our Chatbot
In this subsection,we will upgrade the chatbot above by using Panel’s ChatInterface widget. Another upgrade is that we change the LLM to gpt-3.5-turbo.
First we will define a function for Chatbot to load documents, split documents, define embedding, create vector database from data, define retriever, and create a chatbot chain.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
def load_db(file, chain_type, k):
# load documents
loader = PyPDFLoader(file)
documents = loader.load()
# split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# define embedding
embeddings = OpenAIEmbeddings()
# create vector database from data
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# define retriever
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(model_name=llm_name, temperature=0), chain_type=chain_type, retriever=retriever, return_source_documents=True, return_generated_question=True)
return qa
Next we will define the Chatbot by the code below.
import panel as pn
import param
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/outdoor/Outdoor-Basics.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True)
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
Finally, we will create the chatbot by the code below.
cb = cbfs()
file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
tab1 = pn.Column(pn.Row(inp), pn.layout.Divider(), pn.panel(conversation, loading_indicator=True, height=300), pn.layout.Divider())
tab2= pn.Column(pn.panel(cb.get_lquest), pn.layout.Divider(), pn.panel(cb.get_sources ))
tab3= pn.Column(pn.panel(cb.get_chats), pn.layout.Divider())
tab4=pn.Column(pn.Row( file_input, button_load, bound_button_load), pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )), pn.layout.Divider(), pn.Row(jpg_pane.clone(width=400)))
dashboard = pn.Column(pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')), pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4)))
dashboard
The following figures show the performance of the Chatbot. From these figures, we can see that the Chatbot works very well with Panel’s chat interface. In addition, it is also observed that the Chatbot has good memory and can answer question and follow up questions very naturally.
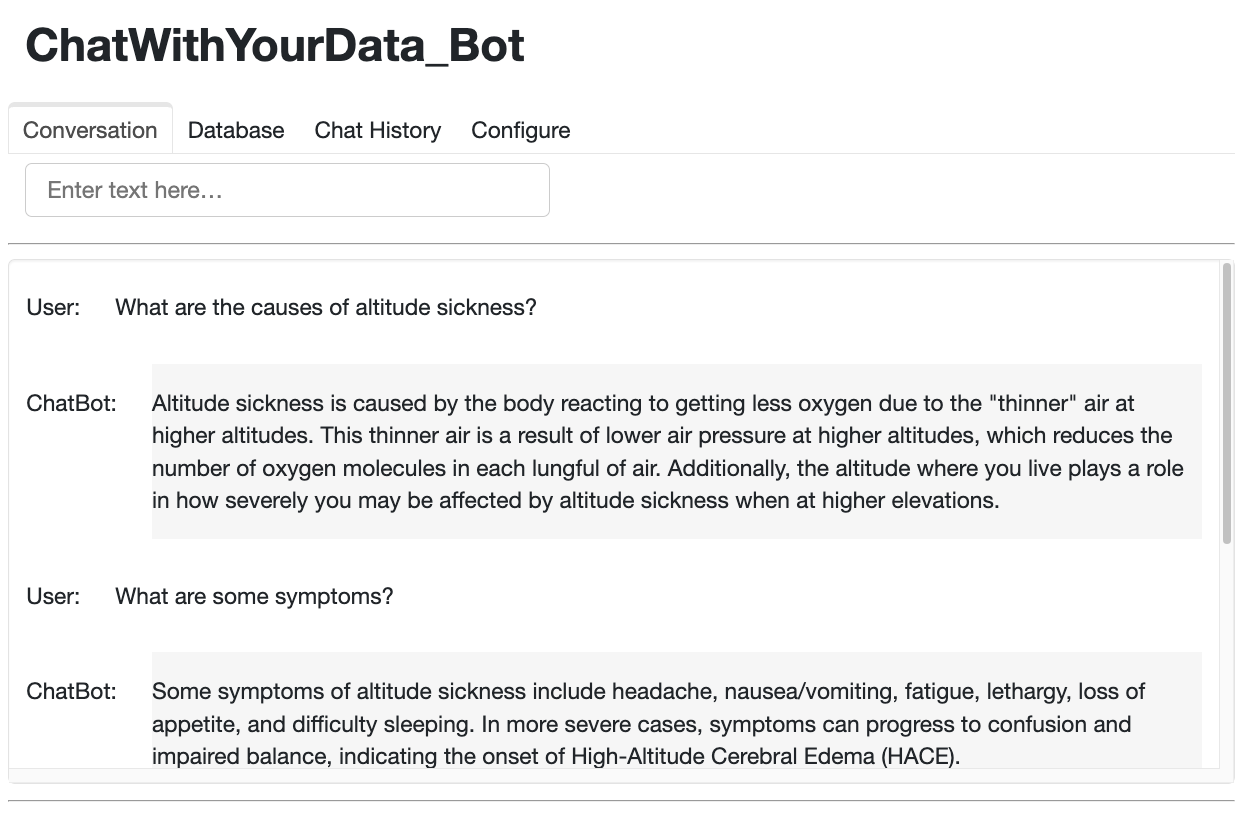
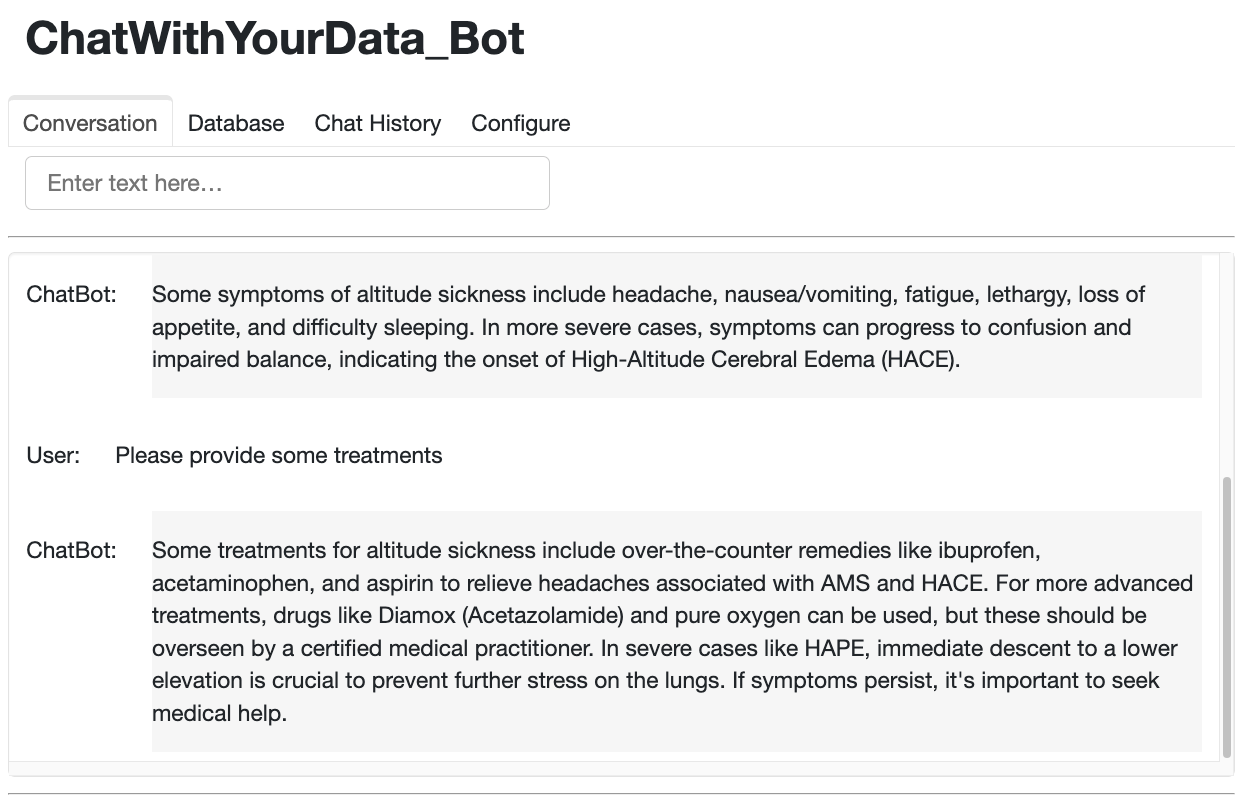
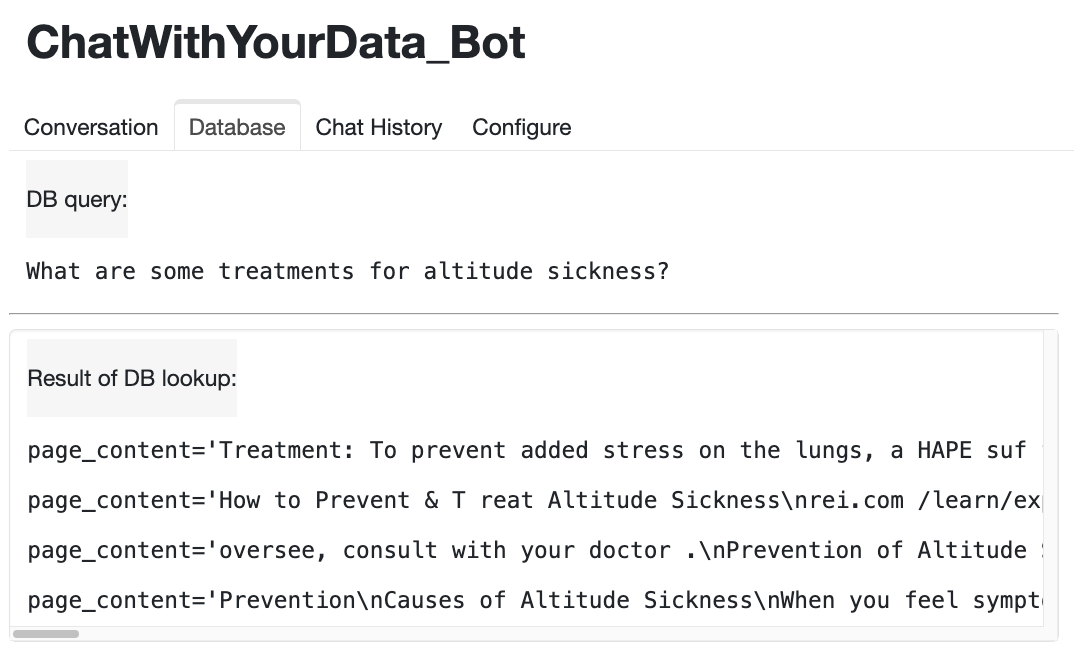

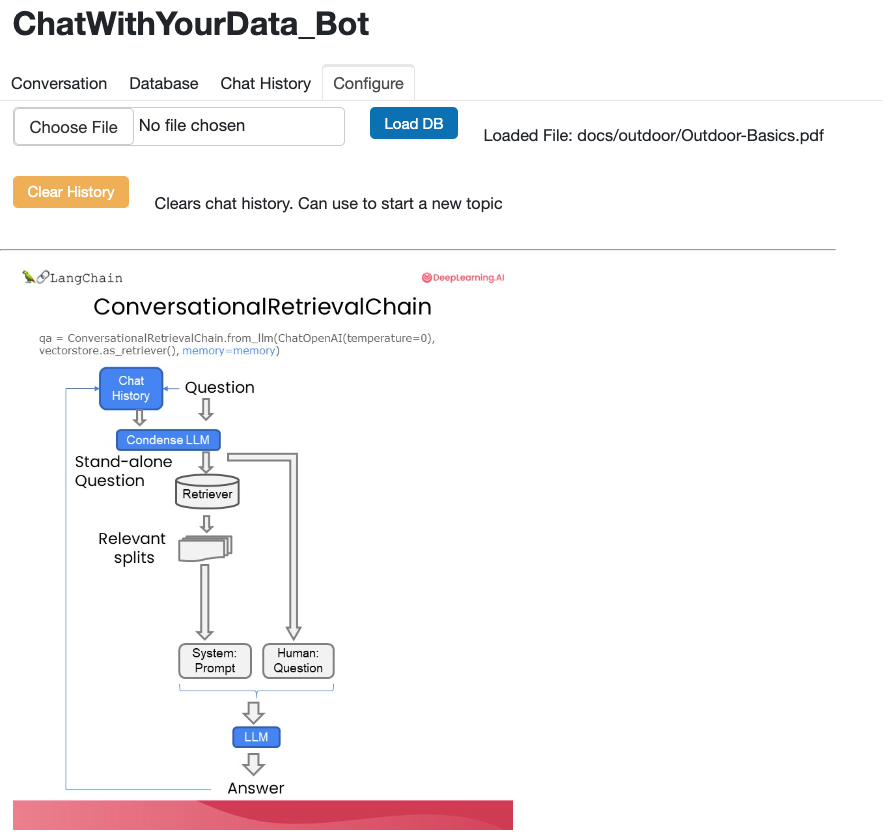
5. Conclusions
In this project, we have built a Retrieval-Augmented Generation Chatbot with the help of LangChain that can answer questions from internal documentation and have memory. Furthermore, we have integrated it with Panel’s chat interface to make the chatbot more user-friendly.
References:
Source of hero image: https://www.haptik.ai/blog/how-does-a-chatbot-learn-on-its-own/
Source of images in this post: https://learn.deeplearning.ai/langchain-chat-with-your-data
- Natural Language Processing
- Generative Question Answering (QA)
- ChatBot
- Chroma
- cohere
- OpenAI
- Retrieval-Augmented Generation (RAG)
- LangChain