Project 7: Extractive QA with a Fine-Tuned BERT
1. Overview
In this project, we will build a Bidirectional Encoder Representations from Transformers (BERT) based model for a different Natural Language Processing task – Question Answering. The model will be fine-tuned on the Conversational Question Answering Challenge (CoQA) dataset from Stanford University.
The Python Notebook containing the complete model development process and the data used in this project can be found at Google Drive.
2. Question Answering (QA)
Question Answering, particularly Extraction-based Question Answering, is another type of Natural Language Processing task. As shown in the figure (source) below, its input has multiple sequences and its output is copied from input.
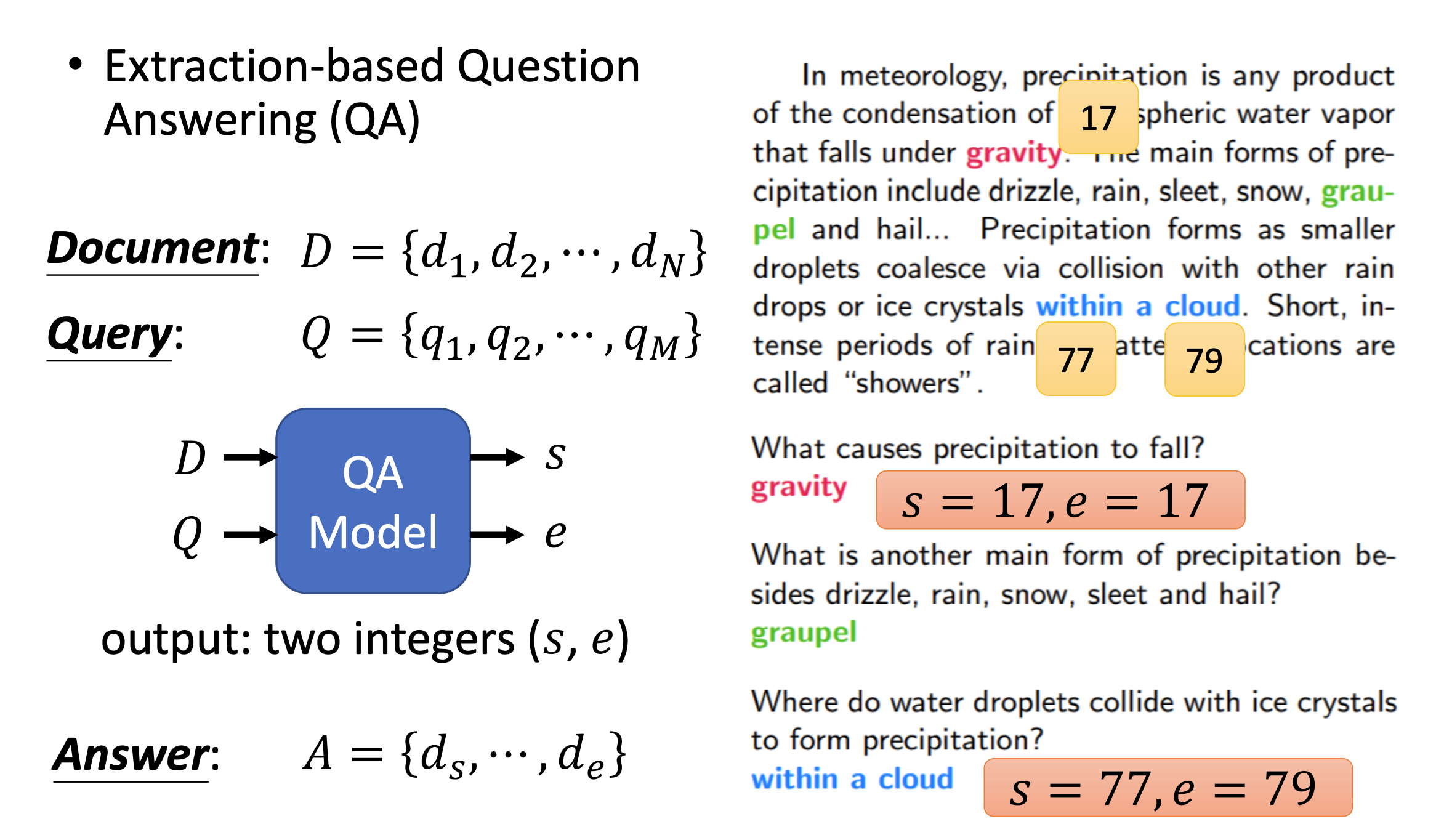
An example of QA from Professor Hung-yi Lee of National Taiwan University (NTU) website is shown below. In particular, to solve the QA problem, the QA model will take both the Document, D = {d1, d2, …, dN} and the Query, Q = {q1, q2, …, qM}, as its input. After processing the data, the QA model will then output two integers: one corresponds to the location in D where the answer starts (s), and the other corresponds to the location in D where the answer ends (e). The answer will be A = {ds, …, de}.
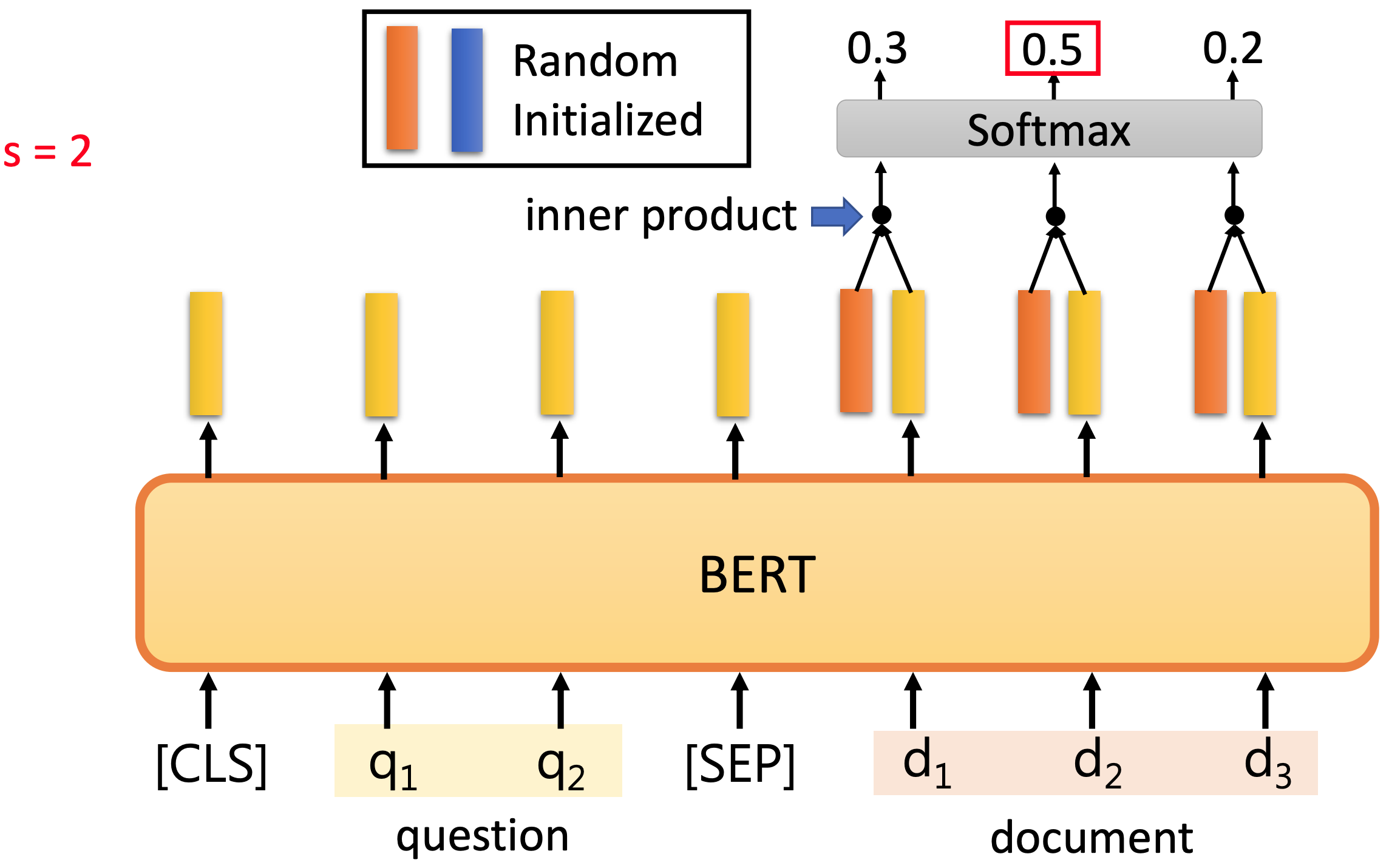
How does BERT-based QA model solve this problem? Generally, a BERT-based QA model will add a task specific layer to the output of BERT pre-trained model. In the two figures source below, two random initialized vectors are added, where the red vector is to detect the answer start location, and the blue vector is to determine the answer end location. To determine the location where answer starts, the red vector will take inner product with each output vector of BERT corresponds to the document D, and then take a softmax to find the location of the start of the answer, s
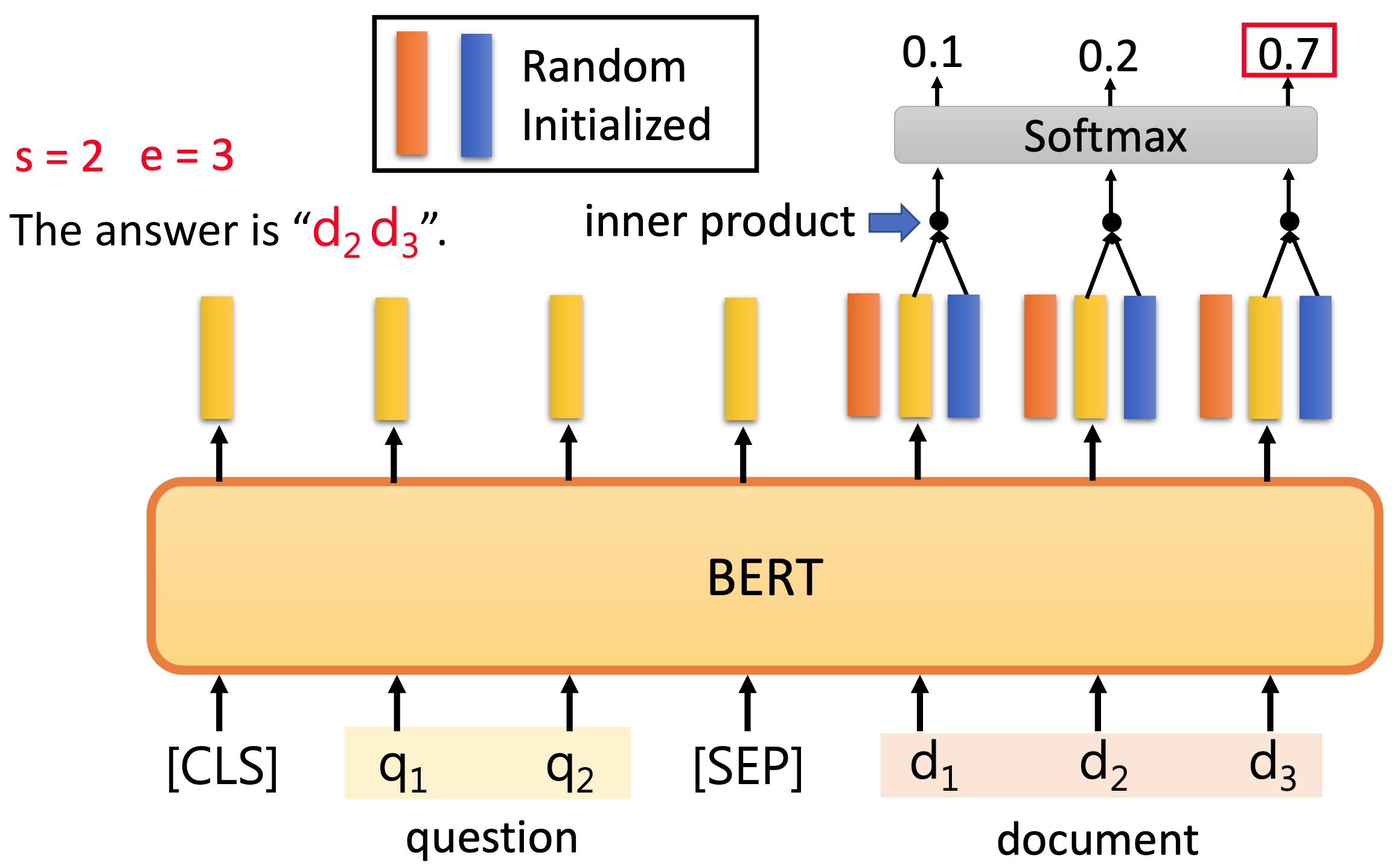
Similarly, to determine the location where answer ends, the blue vector will take inner product with each output vector of BERT corresponds to the document D, and then take a softmax to find the location of the end of the answer, e. After both s and e are determined, the final answer will be A = {ds, …, de}.
3. Model development
3.1. Data Pre-Processing
The dataset we use in this project is the Conversational Question Answering Challenge (CoQA) dataset from Stanford University. This dataset has 7199 records in the train_dev set and 500 records in the test set. The text box below shows the first record from the train_dev set. Here, we can see that each record is saved as a dictionary with 7 keys: source, id, filename, story, questions, answers, and name. Among these keys, story, questions, and answers are important to us, because they corresponds to the Document, Question, and ground truth Answer for our QA model.
Two important points here: (1) each story may be used for multiple questions and answers. Here for brevity we only displayed 3 questions and 3 answers but in the actual data set this story are used by 20 questions and 20 answers. (2) There might be minor imperfection in the dataset. For example, for the second question ‘what is the library for?’, the answer provided is ‘he Vatican Library is a research library’, which should be ‘The Vatican Library is a research library’. If we take a close look at the Document we can find the root cause of this interesting answer is the raw text: ‘\n\nThe Vatican Library is a research library for history, law, philosophy, science and theology.’ So ‘\n’, which is used to add a new line, causes this issue.
{'source': 'wikipedia',
'id': '3zotghdk5ibi9cex97fepx7jetpso7',
'filename': 'Vatican_Library.txt',
'story': 'The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, located in Vatican City. Formally established in 1475, although it is much older, it is one of the oldest libraries in the world and contains one of the most significant collections of historical texts. It has 75,000 codices from throughout history, as well as 1.1 million printed books, which include some 8,500 incunabula. \n\nThe Vatican Library is a research library for history, law, philosophy, science and theology. The Vatican Library is open to anyone who can document their qualifications and research needs. Photocopies for private study of pages from books published between 1801 and 1990 can be requested in person or by mail. \n\nIn March 2014, the Vatican Library began an initial four-year project of digitising its collection of manuscripts, to be made available online. \n\nThe Vatican Secret Archives were separated from the library at the beginning of the 17th century; they contain another 150,000 items. \n\nScholars have traditionally divided the history of the library into five periods, Pre-Lateran, Lateran, Avignon, Pre-Vatican and Vatican. \n\nThe Pre-Lateran period, comprising the initial days of the library, dated from the earliest days of the Church. Only a handful of volumes survive from this period, though some are very significant.',
'questions': [{'input_text': 'When was the Vat formally opened?', 'turn_id': 1},
{'input_text': 'what is the library for?', 'turn_id': 2},
{'input_text': 'for what subjects?', 'turn_id': 3},
...],
'answers': [{'span_start': 151,
'span_end': 179,
'span_text': 'Formally established in 1475',
'input_text': 'It was formally established in 1475',
'turn_id': 1},
{'span_start': 454,
'span_end': 494,
'span_text': 'he Vatican Library is a research library',
'input_text': 'research',
'turn_id': 2},
{'span_start': 457,
'span_end': 511,
'span_text': 'Vatican Library is a research library for history, law',
'input_text': 'history, and law',
'turn_id': 3},
...],
'name': 'Vatican_Library.txt'}
Next we will extract the text, question, answer, answer_start, answer_end from the raw dataset, as shown in the code block below. Also we will clean up the data set by removing null records. Finally, we get 107,286 records in training set and 7,918 records in test set, and the first 5 rows of the processed train_dev data set are shown below.
#required columns in our dataframe
cols = ["text","question","answer","answer_start","answer_end"]
#list of lists to create our dataframe
comp_list = []
for index, row in coqa_train_dev.iterrows():
for i in range(len(row["data"]["questions"])):
temp_list = []
temp_list.append(row["data"]["story"])
temp_list.append(row["data"]["questions"][i]["input_text"])
temp_list.append(row["data"]["answers"][i]["span_text"])
temp_list.append(row["data"]["answers"][i]["span_start"])
temp_list.append(row["data"]["answers"][i]["span_end"])
comp_list.append(temp_list)
new_df_train_dev = pd.DataFrame(comp_list, columns=cols)
#saving the dataframe to csv file for further loading
new_df_train_dev.to_csv("CoQA_data_train_dev.csv", index=False)

In order to make the input data compatible with BERT, we need to tokenize the data using the code block below. One particular trick we find helpful is doc_stride, which means the distance between the start position of two consecutive windows. For example, in the figure above, the answer_start of last row is 769 and the answer_end is 879, which means the length of the document is larger than 512, which is the maximum length for BERT. doc_stride will split the document into several shorter segments and can successfully fix this issue.
class QA_Dataset(Dataset):
def __init__(self, split, data_sets):
self.split = split
self.data_sets = data_sets
self.max_seq_len = 512
self.max_question_len = 509
self.num_doc_stride = 8
def __len__(self):
return len(self.data_sets)
def __getitem__(self, idx):
question = self.data_sets["question"][idx]
tokenized_question = tokenizer(question, add_special_tokens=False)
tokenized_question_input_ids = tokenized_question['input_ids']
actual_question_len = len(tokenized_question_input_ids)
paragraph = self.data_sets["text"][idx]
tokenized_paragraph = tokenizer(paragraph, add_special_tokens=False, return_offsets_mapping=True)
tokenized_paragraph_input_ids = tokenized_paragraph['input_ids']
full_paragraph_len = len(tokenized_paragraph_input_ids)
max_paragraph_len_1 = 512 - 3 - actual_question_len
max_paragraph_len = min(full_paragraph_len, max_paragraph_len_1)
doc_stride = 1
answers = self.data_sets["answer"][idx]
start_char = self.data_sets["answer_start"][idx]
end_char = self.data_sets["answer_end"][idx]
offsets = tokenized_paragraph["offset_mapping"]
len_offsets = len(offsets)
token_start_index = 0
answer_start_token_0 = 0
token_end_index = len(offsets) - 1
answer_end_token_0 = len(offsets) - 1
num_doc_stride = self.num_doc_stride
for k1 in range(0, len_offsets, 1):
if start_char >= offsets[k1][0] and start_char <= offsets[k1][1]:
answer_start_token_0 = k1
if k1 <= len_offsets-2 and start_char == offsets[k1][1]:
answer_start_token_0 = k1 + 1
break;
break;
if k1 <= len_offsets-2 and start_char >= offsets[k1][1] and start_char <= offsets[k1+1][0]:
answer_start_token_0 = k1 + 1
break;
for k2 in range(len_offsets-1, -1, -1):
if end_char >= offsets[k2][0] and end_char <= offsets[k2][1]:
answer_end_token_0 = k2
if k2 <= len_offsets-2 and end_char == offsets[k2][1]:
answer_end_token_0 = k2 + 1
break;
break;
if k2 >=1 and end_char >= offsets[k2-1][1] and end_char <= offsets[k2][0]:
answer_end_token_0 = k2
break;
if answer_start_token_0 == answer_end_token_0:
if answer_end_token_0 == 0:
answer_end_token_0 = answer_end_token_0 + 1
elif answer_start_token_0 == len_offsets-1:
answer_start_token_0 = answer_start_token_0 - 1
else:
answer_end_token_0 = answer_end_token_0 + 1
if self.split == "train":
mid = (answer_start_token_0 + answer_end_token_0) // 2
rand_len = np.random.uniform(low=0.1, high=0.9)
paragraph_start_0 = mid - max_paragraph_len * rand_len
paragraph_start_0 = (np.rint(paragraph_start_0)).astype(int)
min1 = paragraph_start_0
min2 = full_paragraph_len - max_paragraph_len
min3 = answer_start_token_0
paragraph_start = max(0, min(min1, min2, min3))
paragraph_end = paragraph_start + max_paragraph_len
input_ids_question = [101] + tokenized_question.input_ids[:self.max_question_len] + [102]
input_ids_paragraph = tokenized_paragraph.input_ids[paragraph_start : paragraph_end] + [102]
answer_start_token = answer_start_token_0 - paragraph_start + len(input_ids_question)
answer_end_token = answer_end_token_0 - paragraph_start + len(input_ids_question)
input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)
return torch.tensor(input_ids), torch.tensor(token_type_ids), torch.tensor(attention_mask), answer_start_token, answer_end_token
# Validation/Testing
else:
answer1 = tokenized_paragraph_input_ids[answer_start_token_0 : answer_end_token_0]
answer2 = torch.tensor(answer1)
input_ids_list, token_type_ids_list, attention_mask_list = [], [], []
if full_paragraph_len <= max_paragraph_len:
input_ids_question = [101] + tokenized_question.input_ids[: self.max_question_len] + [102]
input_ids_paragraph = tokenized_paragraph.input_ids[ : full_paragraph_len] + [102]
# Pad sequence and obtain inputs to model
input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)
input_ids_list.append(input_ids)
token_type_ids_list.append(token_type_ids)
attention_mask_list.append(attention_mask)
else:
# Paragraph is split into several windows, each with start positions separated by step "doc_stride"
len_diff = full_paragraph_len - max_paragraph_len
doc_stride = math.ceil(len_diff * 1./num_doc_stride)
for i in range(0, len_diff+doc_stride, doc_stride):
# Slice question/paragraph and add special tokens (101: CLS, 102: SEP)
input_ids_question = [101] + tokenized_question.input_ids[: self.max_question_len] + [102]
input_ids_paragraph = tokenized_paragraph.input_ids[i : i + max_paragraph_len] + [102]
# Pad sequence and obtain inputs to model
input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)
input_ids_list.append(input_ids)
token_type_ids_list.append(token_type_ids)
attention_mask_list.append(attention_mask)
return torch.tensor(input_ids_list), torch.tensor(token_type_ids_list), torch.tensor(attention_mask_list), answer2
def padding(self, input_ids_question, input_ids_paragraph):
padding_len = self.max_seq_len - len(input_ids_question) - len(input_ids_paragraph)
input_ids = input_ids_question + input_ids_paragraph + [0] * padding_len
token_type_ids = [0] * len(input_ids_question) + [1] * len(input_ids_paragraph) + [0] * padding_len
attention_mask = [1] * (len(input_ids_question) + len(input_ids_paragraph)) + [0] * padding_len
return input_ids, token_type_ids, attention_mask
The figure below shows the pre-processed input data ready for BERT model. Here for each record, it has 5 parts: (1) a tensor for tokenized ids (i.e., ids of tokenized words), (2) a tensor indicating token_type_ids (i.e., question or document), (3) a tensor indicating attention_mask (i.e., boundary of padding, for parallel processing propose), (4) location in document where the answer starts, and (5) location in document where the answer ends.
3.2. Model Training and Testing
In this project, we will build our model based on the ‘bertForQuestionAnswering’ model that are available on huggingface. Some of the model hyperparameters are listed below. Two key points: (1) instead of constant learning rate, we use Cosine Annealing learning rate and employ scheduler to adjust the learning rate automatically; (2) Since we use T4 GPUs on Google Colab for training, we use mixed precision training and the training speed increase significantly.
optimizer = Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.999), eps=1e-08)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=1000)
fp16_training = True
if fp16_training:
accelerator = Accelerator(mixed_precision="fp16")
else:
accelerator = Accelerator()
model, optimizer, train_loader = accelerator.prepare(model, optimizer, train_loader)
The code block below is for the training of the BERT-based QA model.
model.train()
dev_acc_best = 0
step = 1
for epoch in range(num_epoch):
if epoch <= skip_epoch: # Skip first several epoches
print(" ")
print("skipping train_set epoch: ", epoch)
for data in tqdm(train_loader):
data = [i for i in data]
if validation:
print("skipping test_set epoch: ", epoch)
for data in tqdm(test_loader):
data = [i for i in data]
if epoch > skip_epoch:
print(" ")
print("epoch: ", epoch)
print("Start Training ...")
train_loss = train_acc = 0
for data in tqdm(train_loader):
# Load all data into GPU
data = [i.to(device) for i in data]
# Model inputs: input_ids, token_type_ids, attention_mask, start_positions, end_positions (Note: only "input_ids" is mandatory)
# Model outputs: start_logits, end_logits, loss (return when start_positions/end_positions are provided)
output = model(input_ids=data[0], token_type_ids=data[1], attention_mask=data[2], start_positions=data[3], end_positions=data[4])
# Choose the most probable start position / end position
start_index = torch.argmax(output.start_logits, dim=1)
end_index = torch.argmax(output.end_logits, dim=1)
# Prediction is correct only if both start_index and end_index are correct
train_acc += ((start_index == data[3]) & (end_index == data[4])).float().mean()
train_loss += output.loss
accelerator.backward(output.loss)
step += 1
optimizer.step()
scheduler.step()
optimizer.zero_grad()
if step % logging_step == 0:
lr = optimizer.param_groups[0]["lr"]
print(f"Epoch {epoch + 1} | Step {step} | learning_rate = {lr:.3e} | loss = {train_loss.item() / logging_step:.4f} | acc = {train_acc / logging_step:.4f}")
train_loss = train_acc = 0
print("Saving Model ...")
model_save_dir = "saved_model"
model.save_pretrained(model_save_dir)
if validation:
print("Evaluating Dev Set ...")
model.eval()
with torch.no_grad():
dev_acc = 0
for i, data in enumerate(tqdm(test_loader)):
answer_truth1 = tokenizer.convert_ids_to_tokens(data[3][0])
answer_truth2 = ' '.join(answer_truth1)
output = model(input_ids=data[0].squeeze(dim=0).to(device), token_type_ids=data[1].squeeze(dim=0).to(device),
attention_mask=data[2].squeeze(dim=0).to(device))
answer = ''
max_prob = float('-inf')
num_of_windows = data[0].shape[1]
for k in range(num_of_windows):
# Obtain answer by choosing the most probable start position / end position
start_prob, start_index = torch.max(output.start_logits[k], dim=0)
end_prob, end_index = torch.max(output.end_logits[k], dim=0)
start_prob = start_prob.item()
start_index = start_index.item()
end_prob = end_prob.item()
end_index = end_index.item()
# Probability of answer is calculated as sum of start_prob and end_prob
# prob = start_prob + end_prob
if end_index < start_index:
prob = float('-inf')
answer_pred = data[0][0][k][0:1]
else:
prob = start_prob + end_prob
if start_index == end_index:
if end_index == 0:
print("check - 1")
end_index = end_index + 1
elif start_index == len(data[0][0][k])-1:
print("check - 2")
start_index = start_index - 1
else:
print("check - 3")
end_index = end_index + 1
# Replace answer if calculated probability is larger than previous windows
if prob > max_prob:
max_prob = prob
answer_pred = data[0][0][k][start_index : end_index ]
answer_pred1 = tokenizer.convert_ids_to_tokens(answer_pred)
answer_pred2 = ' '.join(answer_pred1)
dev_acc0 = (answer_truth2 == answer_pred2)
dev_acc = dev_acc + dev_acc0
if i % output_step == 0:
print(" ")
print("i: ", i)
print("answer_truth: ", answer_truth2)
print("answer_pred: ", answer_pred2)
print("dev_acc0: ", dev_acc0)
print("dev_acc: ", dev_acc)
print(f"Validation | Epoch {epoch + 1} | acc = {dev_acc / len(test_loader):.3f}")
model.train()
dev_acc = dev_acc / len(test_loader)
if dev_acc > dev_acc_best:
dev_acc_best = dev_acc
print(f"Saving Best Model | Epoch {epoch + 1} | acc = {dev_acc:.3f}")
model_save_dir = "saved_best_model"
model.save_pretrained(model_save_dir)```
Since we have trained the model for very long time (see attached file P7-QA-training-record.dat in the Google Drive folder), here we just load the checkpoint and run one epoch. For the Training dataset, we achieve accuracy of 83.2%.
!cp /content/drive/MyDrive/210-Projects/710_Question_Answering/P7-QA.tar.gz .
!tar -xf P7-QA.tar.gz
model = BertForQuestionAnswering.from_pretrained("P7-QA").to(device)
Next we move on to evaluate the model’s performance on the test set, with code shown in the block below.
print("Evaluating Dev Set ...")
model.eval()
with torch.no_grad():
dev_acc = 0
for i, data in enumerate(tqdm(test_loader)):
answer_truth1 = tokenizer.convert_ids_to_tokens(data[3][0])
answer_truth2 = ' '.join(answer_truth1)
output = model(input_ids=data[0].squeeze(dim=0).to(device), token_type_ids=data[1].squeeze(dim=0).to(device),
attention_mask=data[2].squeeze(dim=0).to(device))
answer = ''
max_prob = float('-inf')
num_of_windows = data[0].shape[1]
for k in range(num_of_windows):
# Obtain answer by choosing the most probable start position / end position
start_prob, start_index = torch.max(output.start_logits[k], dim=0)
end_prob, end_index = torch.max(output.end_logits[k], dim=0)
start_prob = start_prob.item()
start_index = start_index.item()
end_prob = end_prob.item()
end_index = end_index.item()
# Probability of answer is calculated as sum of start_prob and end_prob
# prob = start_prob + end_prob
if end_index < start_index:
prob = float('-inf')
answer_pred = data[0][0][k][0:1]
else:
prob = start_prob + end_prob
if start_index == end_index:
if end_index == 0:
print("check - 1")
end_index = end_index + 1
elif start_index == len(data[0][0][k])-1:
print("check - 2")
start_index = start_index - 1
else:
print("check - 3")
end_index = end_index + 1
# Replace answer if calculated probability is larger than previous windows
if prob > max_prob:
max_prob = prob
# answer_pred = data[0][0][k][start_index : end_index + 1]
answer_pred = data[0][0][k][start_index : end_index ]
answer_pred1 = tokenizer.convert_ids_to_tokens(answer_pred)
answer_pred2 = ' '.join(answer_pred1)
dev_acc0 = (answer_truth2 == answer_pred2)
dev_acc = dev_acc + dev_acc0
if i % output_step == 0:
print(" ")
print("i: ", i)
print("answer_truth: ", answer_truth2)
print("answer_pred: ", answer_pred2)
print("dev_acc0: ", dev_acc0)
print("dev_acc: ", dev_acc)
print(f"Validation | Epoch {epoch + 1} | acc = {dev_acc / len(test_loader):.3f}")
On the test set, however, the accuracy is only 13.1%, which drops significantly compared to 83.2% on training set. To figure out why there is such big difference in model performance, we output comparisons of 10 ground truth answer and predicted answer from test set, in the figure below. From this figure, we noticed that in most cases the difference between predicted answer and ground truth answer is quite minor – sometimes just a full stop. In addition, we also notice that sometimes the predicted answers are too verbose, while in other times the ground truth answers are too verbose. To fully resolve this issue, we need to go through the dataset thoroughly and clean it up to that the provided ground truth answer are in a consistent style.

3.3. Results on custom inputs
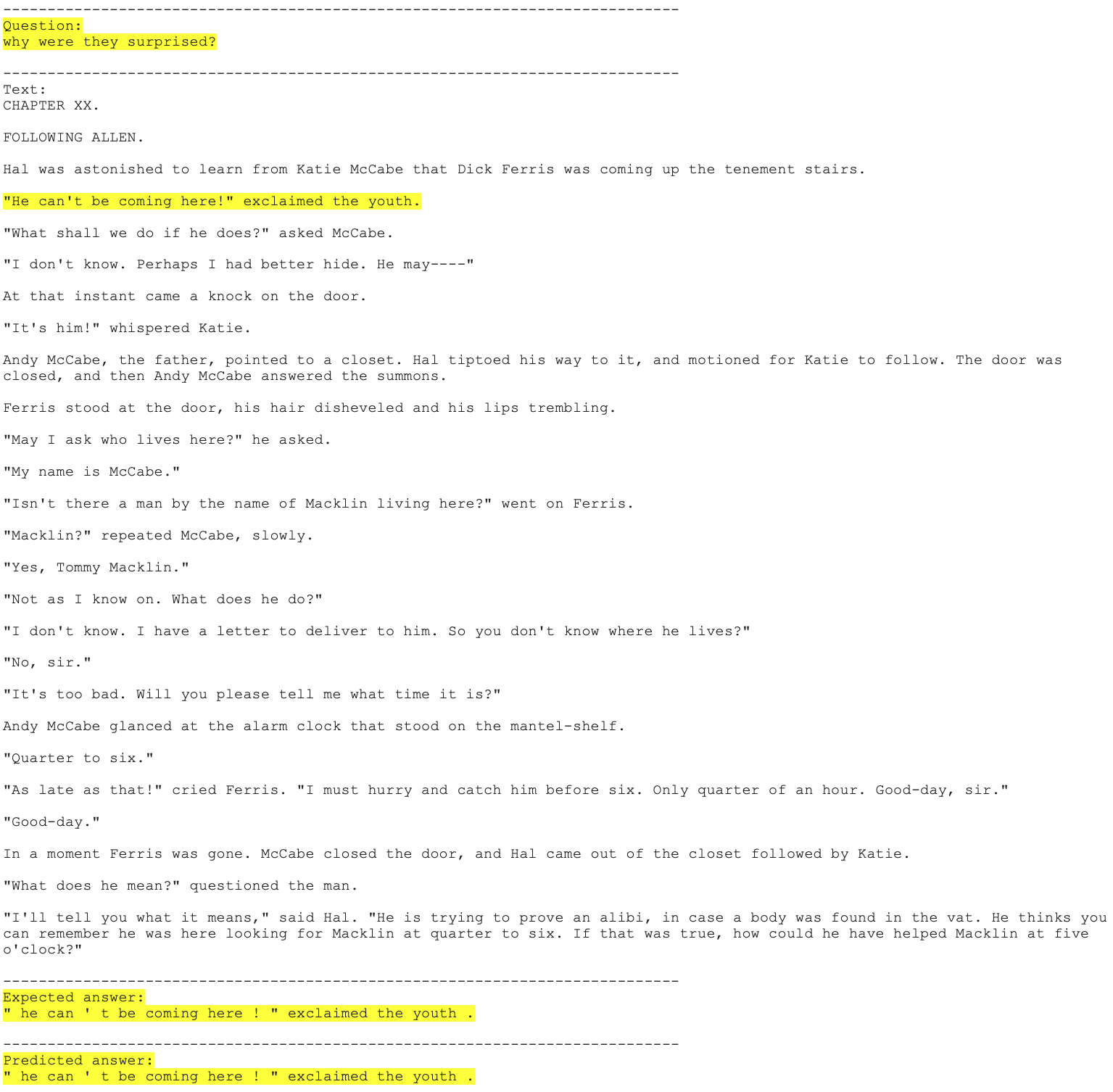
Next we develop a program so that we could manually choose a QA problem from CoQA dataset, make the prediction and shows the Question, Document, ground truth answer, and predicted answer. The code to realize this function is shown below, with two results shown in the following two figures.
# Combined train_set and test_set.
# First 107286 records [0, 107285] are from train_set and last 7918 records [107286, 115203] are from test_set
# qa_item can be given manually or chosen randomly
qa_item = 1789
# qa_item = np.random.randint(0,len(data_all))
data_all = pd.concat([data_train, data_test], ignore_index=True)
data_all = data_all.reset_index(drop=True)
data_qa = data_all.iloc[qa_item:qa_item+1]
data_qa = data_qa.reset_index(drop=True)
qa_set = QA_Dataset("test", data_qa)
qa_loader = DataLoader(qa_set, batch_size=1, shuffle=False, pin_memory=True)
# print("Evaluating Dev Set ...")
model.eval()
with torch.no_grad():
for data in qa_loader:
answer_truth1 = tokenizer.convert_ids_to_tokens(data[3][0])
answer_truth2 = ' '.join(answer_truth1)
output = model(input_ids=data[0].squeeze(dim=0).to(device), token_type_ids=data[1].squeeze(dim=0).to(device),
attention_mask=data[2].squeeze(dim=0).to(device))
answer = ''
max_prob = float('-inf')
num_of_windows = data[0].shape[1]
for k in range(num_of_windows):
# Obtain answer by choosing the most probable start position / end position
start_prob, start_index = torch.max(output.start_logits[k], dim=0)
end_prob, end_index = torch.max(output.end_logits[k], dim=0)
start_prob = start_prob.item()
start_index = start_index.item()
end_prob = end_prob.item()
end_index = end_index.item()
# Probability of answer is calculated as sum of start_prob and end_prob
# prob = start_prob + end_prob
if end_index < start_index:
prob = float('-inf')
answer_pred = data[0][0][k][0:1]
else:
prob = start_prob + end_prob
if start_index == end_index:
if end_index == 0:
print("check - 1")
end_index = end_index + 1
elif start_index == len(data[0][0][k])-1:
print("check - 2")
start_index = start_index - 1
else:
print("check - 3")
end_index = end_index + 1
# Replace answer if calculated probability is larger than previous windows
if prob > max_prob:
max_prob = prob
# answer_pred = data[0][0][k][start_index : end_index + 1]
answer_pred = data[0][0][k][start_index : end_index]
answer_pred1 = tokenizer.convert_ids_to_tokens(answer_pred)
answer_pred2 = ' '.join(answer_pred1)
print(" ")
print("----------------------------------------------------------------------------")
print("Question: ")
print(data_qa["question"][0])
print(" ")
print("----------------------------------------------------------------------------")
print("Text: ")
print(data_qa["text"][0])
print(" ")
print("----------------------------------------------------------------------------")
print("Expected answer: ")
print(answer_truth2)
print(" ")
print("----------------------------------------------------------------------------")
print("Predicted answer: ")
print(answer_pred2)
From these results, we can see that the QA model we built can provide very accurate answers. Given the Documents are much longer than 512 characters (1632 characters and 1478 characters in these examples), it also prove that the doc_stride approach we employed in our model is very successful.

4. Conclusions
In this project, we built a BERT based Natural Language Processing model for Question and Answering task, and the model was fine-tuned on the Conversational Question Answering Challenge (CoQA) dataset from Stanford University. The QA model has amazing performance and can accurately extract the answer from the Document, even when the length of Document is significantly larger than 512. To further improve the performance of the QA model, I would suggest changing from BERT_base model to BERT_large model.
References:
Source of hero image: https://towardsml.wordpress.com/2019/09/17/bert-explained-a-complete-guide-with-theory-and-tutorial/
- Natural Language Processing
- Bidirectional Encoder Representations from Transformers (BERT)
- Question Answering