Project 8: Machine Translation with Transformers
1. Overview
In this project, we will build a neural machine translation model with Fairseq Transformer that can translate English into Chinese naturally. The model will be trained and evaluated on the TED2020 En-Zh Bilingual Parallel Corpus.
The Python Notebook containing the complete model development process and the data used in this project can be found at Google Drive.
2. Machine translation and Transformer
2.1. Brief history of machine translation
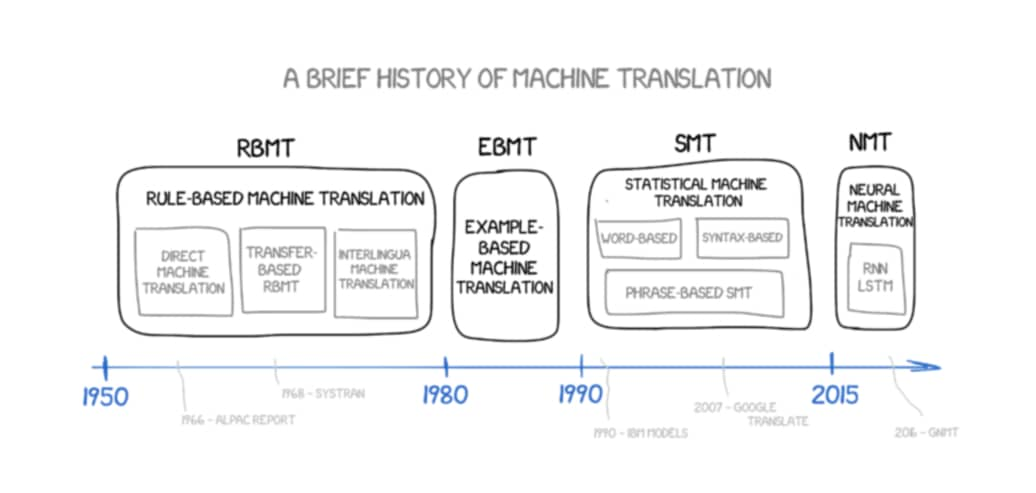
The figure above illustrates the development of Machine Translation from 1950s to today (source). In brief, the development of Machine Translation has 4 main stages: (1) Rule-based Machine Translation (RBMT), (2) Example-based Machine Translation (EBMT), (3) Statistical Machine Translation (SMT), and (4) Neural Machine Translation (NMT). Detailed discussion of each stage can be found in this great article. In the following part of this post, we will focus on the Neural Machine Translation (NMT) stage, because that is where Transformer are developed from.
2.2. Sequence-to-sequence (seq2seq) model
Since 2015, Neural Machine Translation (NMT) has become very popular in machine translation. In this school of methods, sentences from source language and target language are treated as sequences. As a consequence, the machine translation task essentially becomes a sequence generation task, and we can use a Sequence-to-sequence model (aka seq2seq) to complete this task (see picture below).
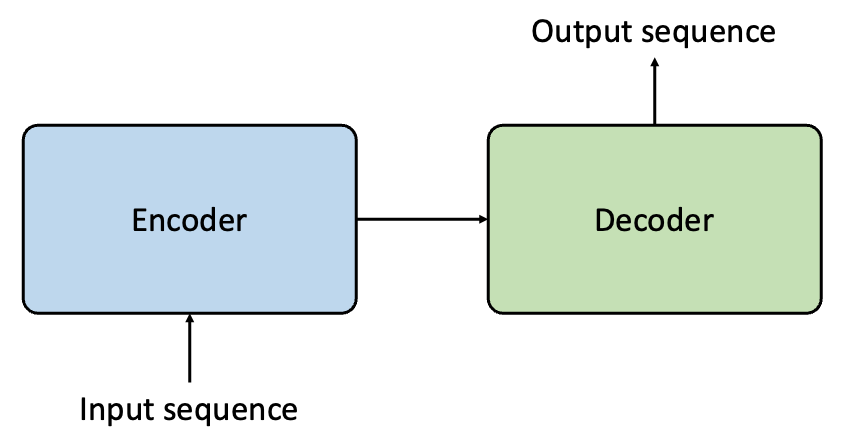
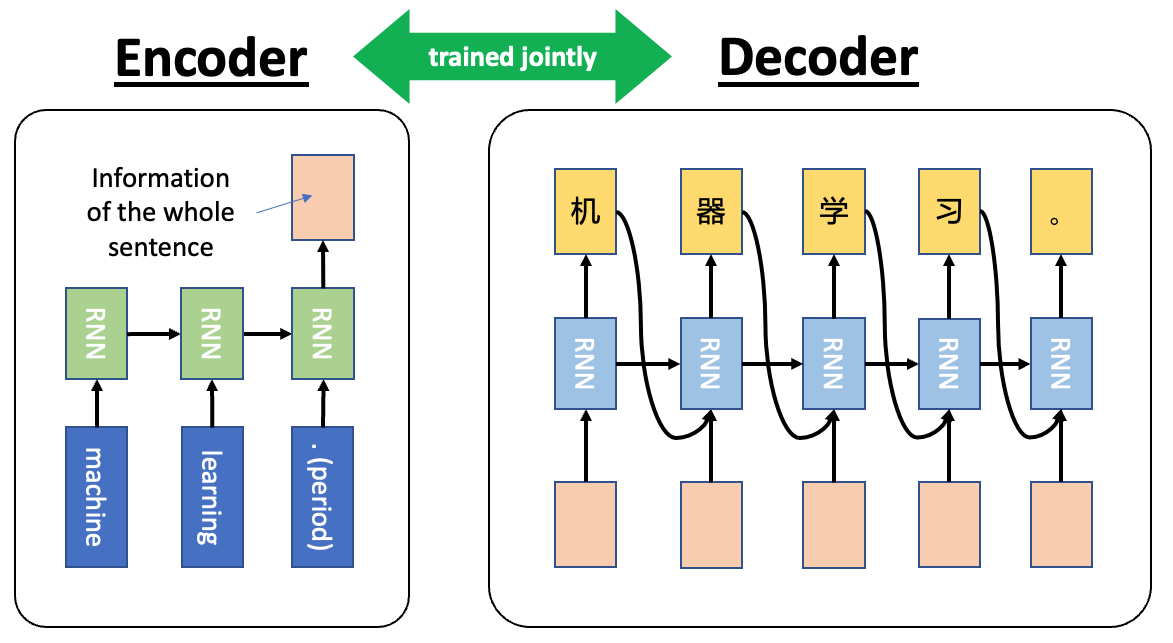
A schematic plot of a Sequence-to-sequence (seq2seq) model is shown in the figure below. Essentially, the seq2seq model contains an Encoder and a Decoder. The Encoder processes the source language input sequentially and shrink the information into a vector using RNN and passes it to the Decoder. The Decoder then processes this information by another RNN and makes predictions in the target language.
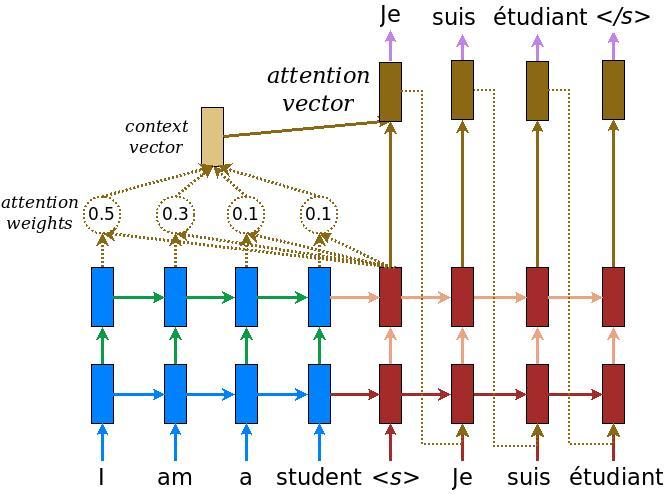
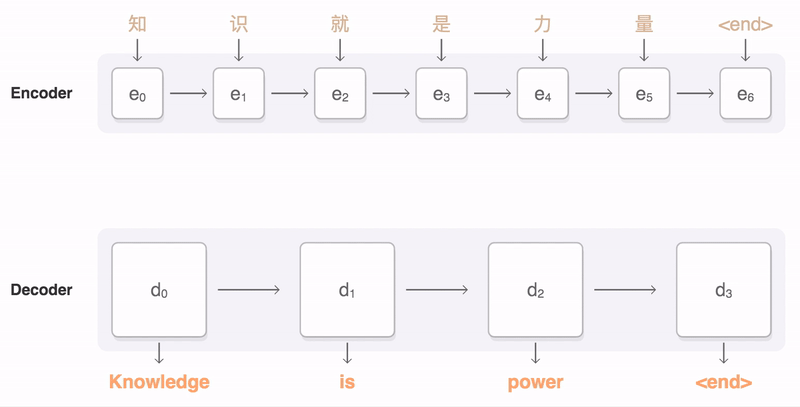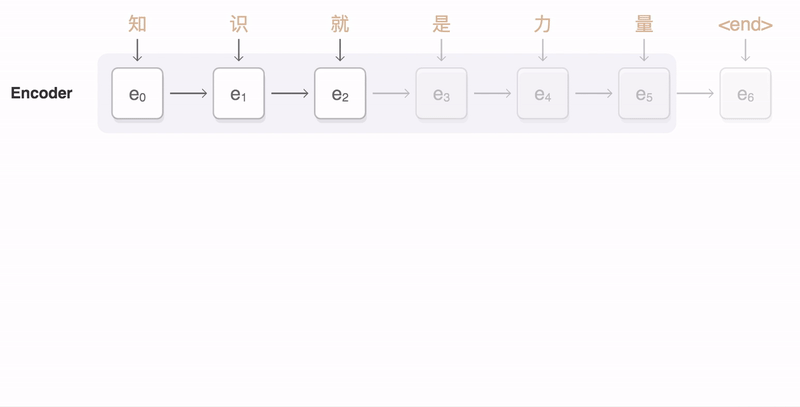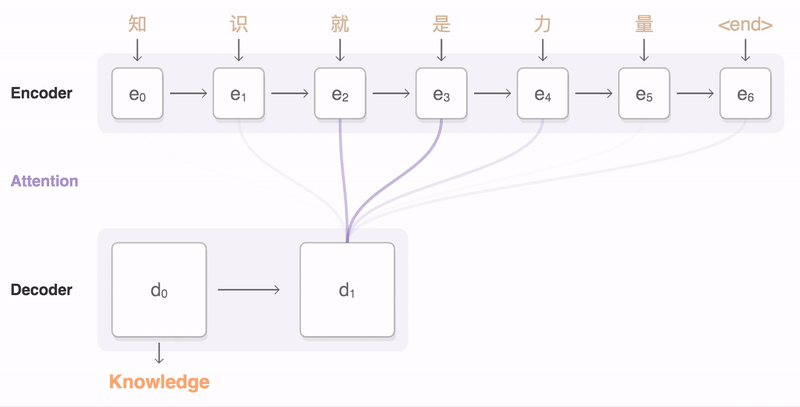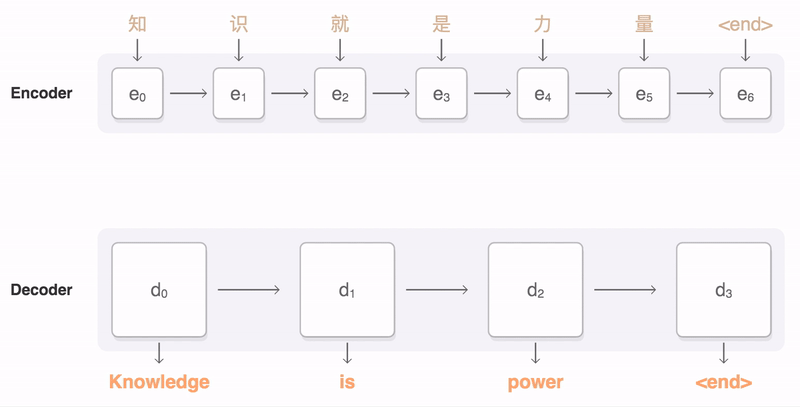
One potential limitation of RNN-based seq2seq model is long sentences (i.e., long-range dependencies). One potential solution is to use Long Short-term Memory (LSTM) cells instead of RNN cells. This approach can effectively alleviate the difficulty, but an even better solution is to employ the attention mechanism. The figure below shows how attention mechanism works in seq2seq model for English-French translation (figure source).
Another great source of information is Google Neural Machine Translation system (GNMT), which can be found in arxiv. GNMT is also illustrated in the figure below (figure source).
On the other hand, since hidden state of RNN or LSTM depends on the previous one, it become very difficult to parallelize and makes it inefficient on GPUs. To resolve this limitation, Google proposed the Transformer model, which is published in the very famous paper Attention Is All You Need. We will take a close look at it in the next section.
2.3. Transformer model
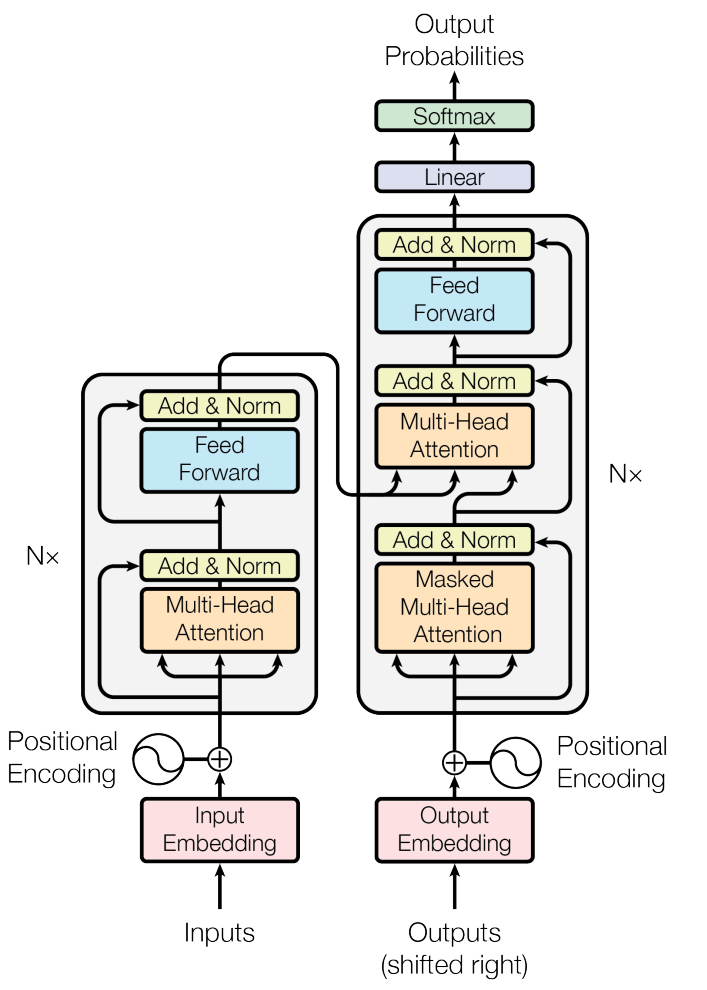
The architecture of the Transformer model is shown above (figure source). In the following part, we will discuss some of the most important features of the Transformer model.
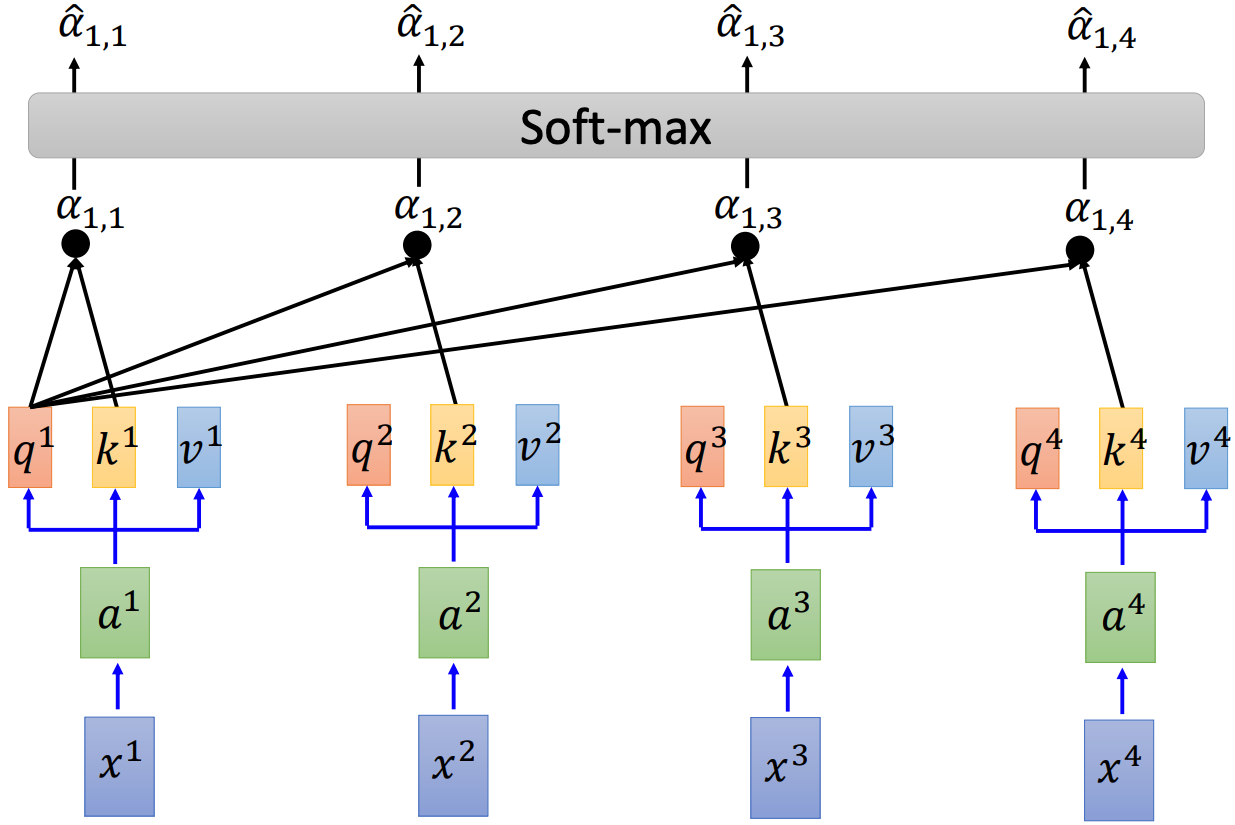
As illustrated in the two figures above (source), three vectors will be generated first for each element of the input sequence:
q: query (to match others) – q^i = W^q a^ik: key (to be matched) – k^i = W^k a^iv: value (information to be extracted) – v^i = W^v a^i
Then we could get the scaled dot-product attention by

here d is the dimension of q and k. Then all the scaled dot-product attention will go through a soft-max layer, so that their values are between 0 and 1 and the sum of their values will be 1.
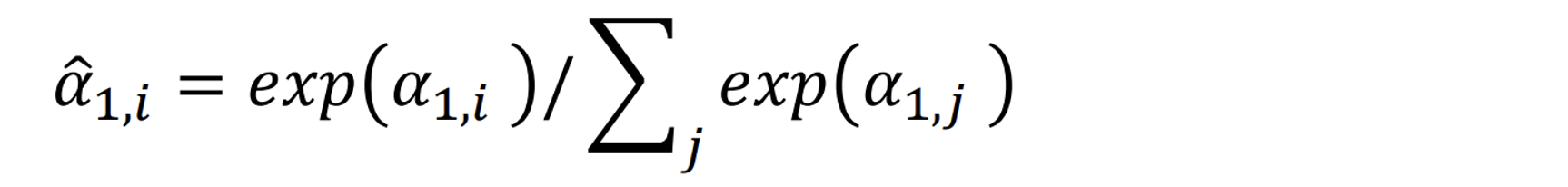
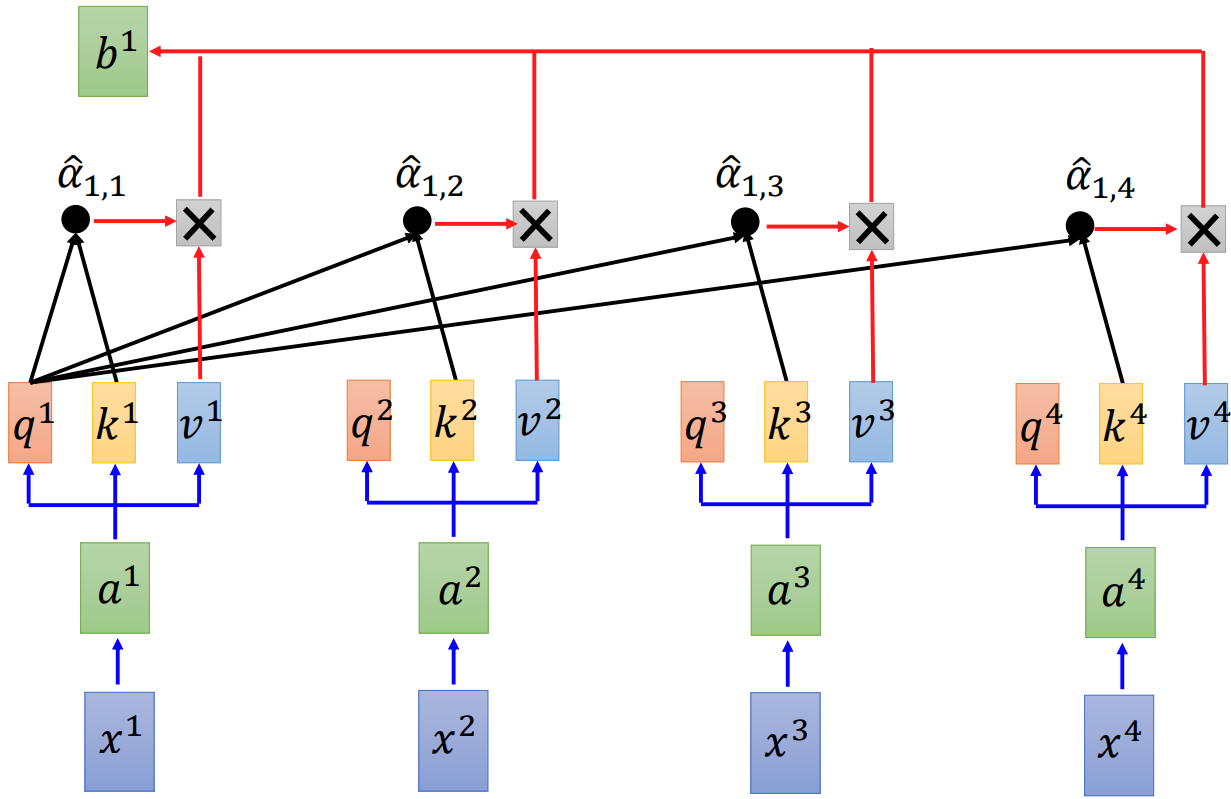
Next we could get the output b^1 by multiplying alpha_hat_1,i with v^i of each element of the input sequence.

The discussion above is a conceptual discussion about how the Self-Attention Layer works. In practice, all these calculations are realized by matrix operations as illustrated in the figure (source) below. Consequently, they can be done extremely efficiently and parallelly, which is ideal for GPUs.
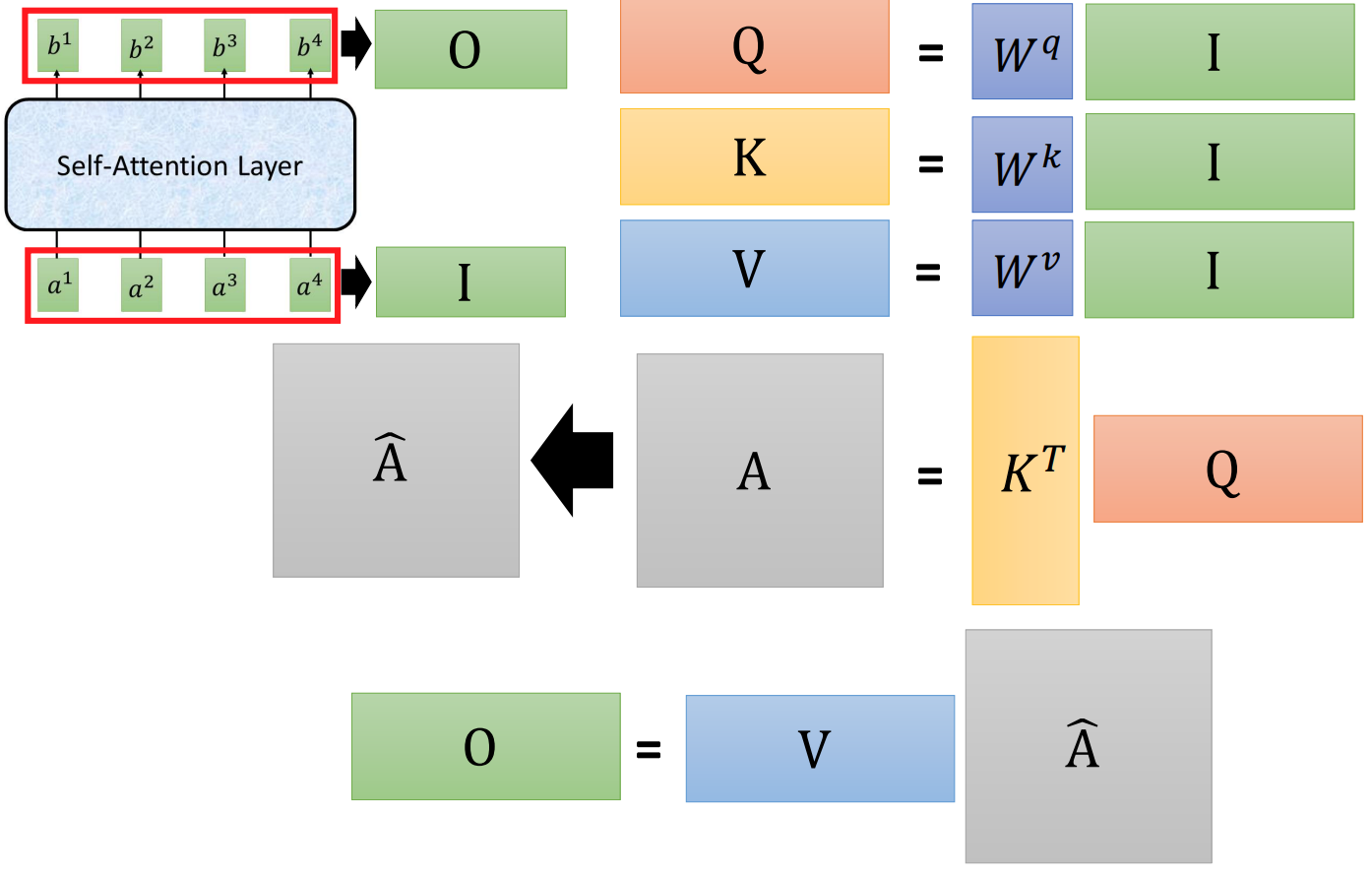
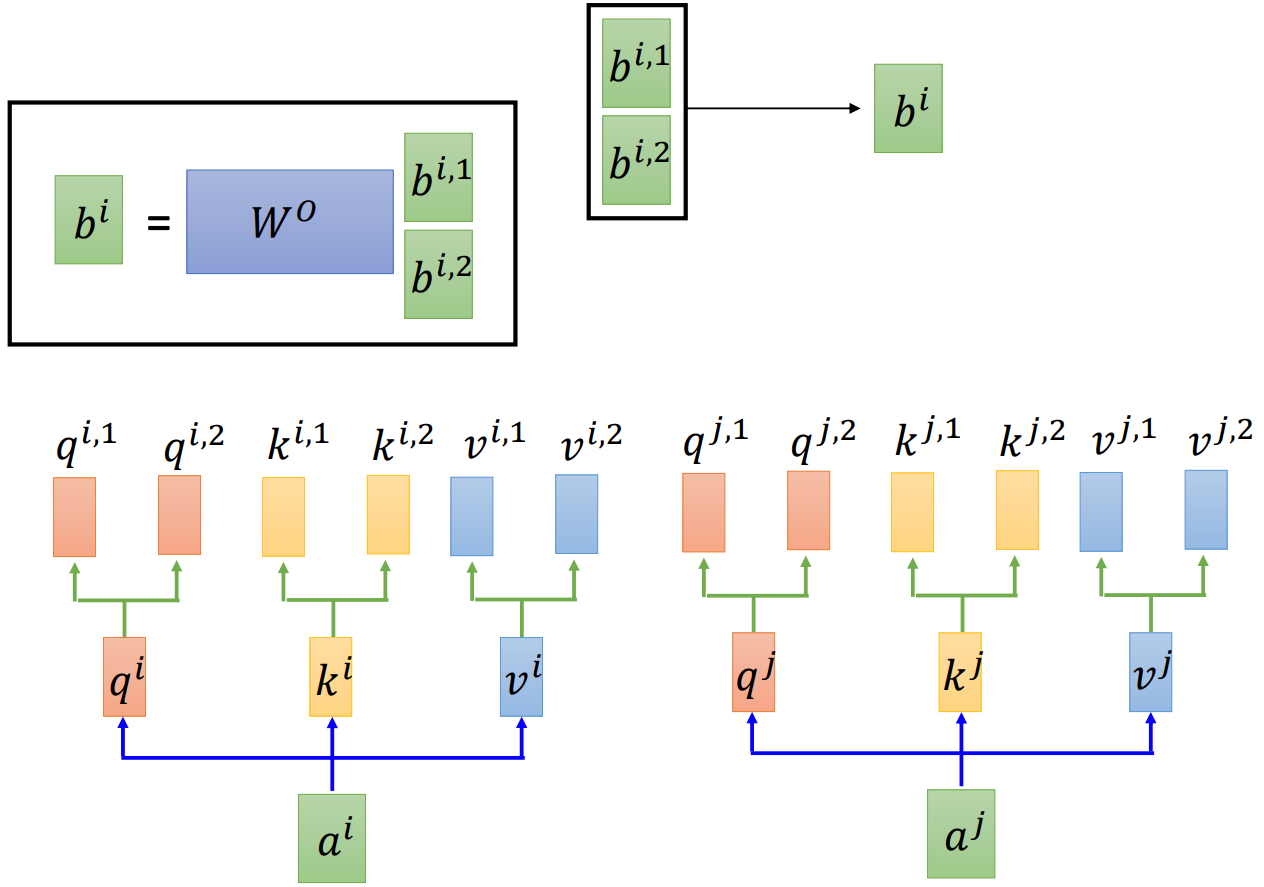
Multi-head attention is another key feature of Transformer, which is illustrated schematically in the figure (source) below. Compared to single-head attention, multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
Since the Transformer processes each element of the input sequence parallelly as one-piece, the information about the order of these elements in the sequence will be lost. On the other hand, the position of each element is critical for the next steps, so a function (shown below) named Positional Encoding (PE) will be added to the embedding vector before the encoder and decoder, which can produces an index that shows the element’s location in the sequence.
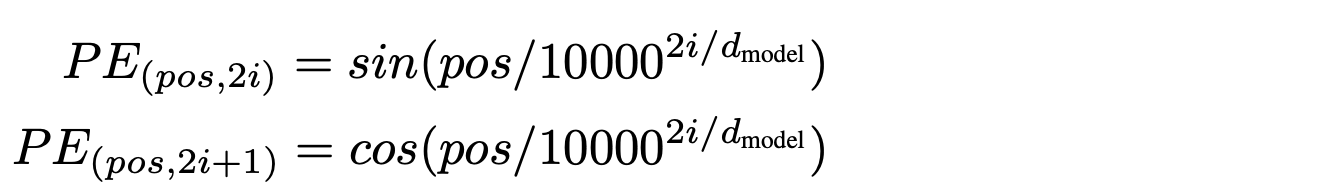
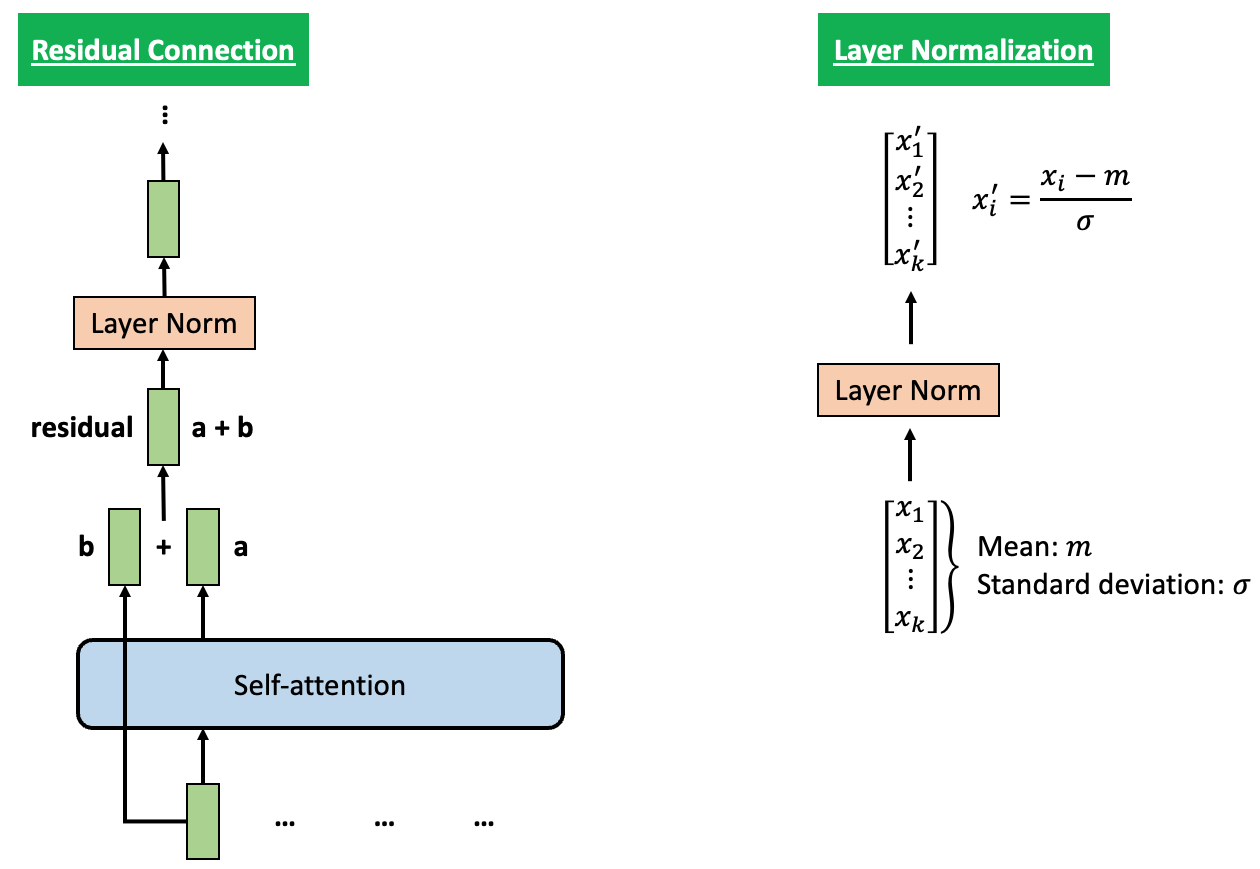
To help stabilize the training process, Residual Connection and Layer Normalization are employed in each Encoder and Decoder, as shown in the figure below.
3. Model development
3.1. Install required packages
To build a Transformer-based model for English-Chinese translation on Google Colab, we need to install required packages first. In particular, the Transformer model toolkit we used in this project is developed by Facebook AI Research (FAIR).
!pip install 'torch>=1.6.0' editdistance matplotlib sacrebleu sacremoses sentencepiece tqdm wandb
!pip install --upgrade jupyter ipywidgets
!git clone https://github.com/pytorch/fairseq.git
!cd fairseq && git checkout 3f6ba43
!pip install --upgrade ./fairseq/
Then we can import the toolkit by the following commands.
from fairseq import utils
from fairseq.tasks.translation import TranslationConfig, TranslationTask
from fairseq.data import iterators
from fairseq.models.transformer import TransformerEncoder, TransformerDecoder
from fairseq.models import FairseqEncoder, FairseqIncrementalDecoder,FairseqEncoderDecoderModel
from fairseq.modules import MultiheadAttention
from fairseq.models.transformer import base_architecture
3.2. Data pre-processing
The dataset we used in this project is the TED2020 English-Chinese bilingual parallel corpus. We could download it from opus.nlpl.eu/TED2020.php. Since I have already download it, to reduce the load of the server, I will copy it from Google Drive. Below also shows some example from the source language (i.e., English) and target language (i.e., Chinese) dataset.
# TED2020 - En-Zh Bilingual Parallel Corpus
# https://opus.nlpl.eu/TED2020.php
!cp -r drive/MyDrive/210-Projects/810_Machine_translation/data/ ./
data_dir = './data/rawdata'
prefix = Path(data_dir).absolute()
# Language
src_lang = 'en'
tgt_lang = 'zh'
data_prefix = f'{prefix}/ted2020.raw'
!head {data_prefix+'.'+src_lang} -n 5
!head {data_prefix+'.'+tgt_lang} -n 5
# Thank you so much, Chris.
# And it's truly a great honor to have the opportunity to come to this stage twice; I'm extremely grateful.
# I have been blown away by this conference, and I want to thank all of you for the many nice comments about what I had to say the other night.
# And I say that sincerely, partly because I need that.
# Put yourselves in my position.
# 非常謝謝你,克里斯。能有這個機會第二度踏上這個演講台
# 真是一大榮幸。我非常感激。
# 這個研討會給我留下了極為深刻的印象,我想感謝大家 對我之前演講的好評。
# 我是由衷的想這麼說,有部份原因是因為 —— 我真的有需要!
# 請你們設身處地為我想一想!
In next step, we will clean up the dataset and split it into training set (95% of data) and validation set (5% of data). Then we will use the following code block to create two dictionaries for the source language and target language. Examples of processed data are also shown below.
vocab_size = 8000
if (prefix/f'spm{vocab_size}.model').exists():
print(f'{prefix}/spm{vocab_size}.model exists. skipping spm_train.')
else:
spm.SentencePieceTrainer.train(
input=','.join([f'{prefix}/train.clean.{src_lang}',
f'{prefix}/valid.clean.{src_lang}',
f'{prefix}/train.clean.{tgt_lang}',
f'{prefix}/valid.clean.{tgt_lang}']),
model_prefix=prefix/f'spm{vocab_size}',
vocab_size=vocab_size,
character_coverage=1,
model_type='unigram', # 'bpe' works as well
input_sentence_size=1e6,
shuffle_input_sentence=True,
normalization_rule_name='nmt_nfkc_cf',
)
spm_model = spm.SentencePieceProcessor(model_file=str(prefix/f'spm{vocab_size}.model'))
in_tag = {
'train': 'train.clean',
'valid': 'valid.clean',
}
for split in ['train', 'valid']:
for lang in [src_lang, tgt_lang]:
out_path = prefix/f'{split}.{lang}'
if out_path.exists():
print(f"{out_path} exists. skipping spm_encode.")
else:
with open(prefix/f'{split}.{lang}', 'w') as out_f:
with open(prefix/f'{in_tag[split]}.{lang}', 'r') as in_f:
for line in in_f:
line = line.strip()
tok = spm_model.encode(line, out_type=str)
print(' '.join(tok), file=out_f)
!head {data_dir+'/'+'/train.'+src_lang} -n 5
!head {data_dir+'/'+'/train.'+tgt_lang} -n 5
# ▁thank ▁you ▁so ▁much ▁, ▁chris ▁.
# ▁and ▁it ' s ▁ t ru ly ▁a ▁great ▁ho n or ▁to ▁have ▁the ▁opportunity ▁to ▁come ▁to ▁this ▁stage ▁ t wi ce ▁; ▁i ' m ▁extreme ly ▁gr ate ful ▁.
# ▁i ▁have ▁been ▁ bl ow n ▁away ▁by ▁this ▁con f er ence ▁, ▁and ▁i ▁want ▁to ▁thank ▁all ▁of ▁you ▁for ▁the ▁many ▁ ni ce ▁ com ment s ▁about ▁what ▁i ▁had ▁to ▁say ▁the ▁other ▁night ▁.
# ▁and ▁i ▁say ▁that ▁since re ly ▁, ▁part ly ▁because ▁i ▁need ▁that ▁.
# ▁put ▁your s el ve s ▁in ▁my ▁po s ition ▁.
# ▁ 非常 謝 謝 你 ▁, ▁ 克 里 斯 ▁。 ▁ 能 有 這個 機會 第二 度 踏 上 這個 演講 台
# ▁ 真 是 一 大 榮 幸 ▁。 ▁我 非常 感 激 ▁。
# ▁這個 研 討 會 給我 留 下 了 極 為 深 刻 的 印 象 ▁, ▁我想 感 謝 大家 對 我 之前 演講 的 好 評 ▁。
# ▁我 是由 衷 的 想 這麼 說 ▁, ▁有 部份 原因 是因為 我 真的 有 需要 ▁!
# ▁ 請 你們 設 身 處 地 為 我想 一 想 ▁!
Then, we will binarize the data with fairseq by preparing the files in pairs for both the source and target languages. The code is shown in the block below.
binpath = Path('./data/data-bin')
if binpath.exists():
print(binpath, "exists, will not overwrite!")
else:
!python -m fairseq_cli.preprocess \
--source-lang {src_lang}\
--target-lang {tgt_lang}\
--trainpref {prefix/'train'}\
--validpref {prefix/'valid'}\
--destdir {binpath}\
--joined-dictionary\
--workers 2
We will use the TranslationTask from fairseq to load the binarized data created above. It has well-implemented data iterator (dataloader) and well-implemented beam search decoder. Also,its built-in task.source_dictionary and task.target_dictionary are also very handy. The code block below shows some highlighted part and example output. Full working code is available here.
task = TranslationTask.setup_task(task_cfg)
task.load_dataset(split="train", epoch=1, combine=True)
task.load_dataset(split="valid", epoch=1)
sample = task.dataset("train")[1]
pprint.pprint(sample)
# {'id': 1,
# 'source': tensor([ 11, 20, 15, 6, 5, 14, 281, 42, 13, 644, 440, 32,
# 79, 12, 59, 9, 2952, 12, 407, 12, 31, 2963, 5, 14,
# 1342, 123, 352, 19, 15, 33, 2975, 42, 582, 149, 579, 7,
# 2]),
# 'target': tensor([ 5, 859, 29, 55, 78, 3239, 1563, 10, 39, 299, 448, 1554,
# 10, 2])}
# ("Source: and it's truly a great honor to have the opportunity to come to this "
# "stage twice ; i'm extremely grateful .")
# 'Target: 真是一大榮幸 。 我非常感激 。'
3.3. Model configuration
First we build a seq2seq class, which is composed of an Encoder and a Decoder. The input sequence will be passed to Encoder first. Then the Decoder will decode according to outputs of previous steps as well as Encoder outputs. Once done decoding, the seq2seq object will return the outputs from the Decoder.
class Seq2Seq(FairseqEncoderDecoderModel):
def __init__(self, args, encoder, decoder):
super().__init__(encoder, decoder)
self.args = args
def forward(self,src_tokens,src_lengths,prev_output_tokens,return_all_hiddens: bool = True,):
encoder_out = self.encoder(src_tokens, src_lengths=src_lengths, return_all_hiddens=return_all_hiddens)
logits, extra = self.decoder(prev_output_tokens,encoder_out=encoder_out,src_lengths=src_lengths,return_all_hiddens=return_all_hiddens,)
return logits, extra
The code block below shows the model initialization function.
def build_model(args, task):
src_dict, tgt_dict = task.source_dictionary, task.target_dictionary
# token embeddings
encoder_embed_tokens = nn.Embedding(len(src_dict), args.encoder_embed_dim, src_dict.pad())
decoder_embed_tokens = nn.Embedding(len(tgt_dict), args.decoder_embed_dim, tgt_dict.pad())
# encoder decoder
encoder = TransformerEncoder(args, src_dict, encoder_embed_tokens)
decoder = TransformerDecoder(args, tgt_dict, decoder_embed_tokens)
# sequence to sequence model
model = Seq2Seq(args, encoder, decoder)
# initialization for seq2seq model
def init_params(module):
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.bias is not None:
module.bias.data.zero_()
if isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
if isinstance(module, MultiheadAttention):
module.q_proj.weight.data.normal_(mean=0.0, std=0.02)
module.k_proj.weight.data.normal_(mean=0.0, std=0.02)
module.v_proj.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.RNNBase):
for name, param in module.named_parameters():
if "weight" in name or "bias" in name:
param.data.uniform_(-0.1, 0.1)
# weight initialization
model.apply(init_params)
return model
Next we will show the architecture related configuration, which is based on the hyperparameters in Table 3 of the very famous paper Attention Is All You Need.
arch_args = Namespace(
encoder_embed_dim=512,
encoder_ffn_embed_dim=2048,
encoder_layers=6,
decoder_embed_dim=512,
decoder_ffn_embed_dim=2048,
decoder_layers=6,
share_decoder_input_output_embed=True,
dropout=0.1,
)
def add_transformer_args(args):
args.encoder_attention_heads=8
args.encoder_normalize_before=True
args.decoder_attention_heads=8
args.decoder_normalize_before=True
args.activation_fn="relu"
args.max_source_positions=1024
args.max_target_positions=1024
base_architecture(arch_args)
add_transformer_args(arch_args)
model = build_model(arch_args, task)
3.4. Optimization
In order to stabilize the training for transformers in its early stages, we will employ the learning rate scheduling technique. As visualized in the figure below, the learning rate will increase linearly for the first warmup_steps training steps, and it will then decrease thereafter proportionally to the inverse square root of the step_number.
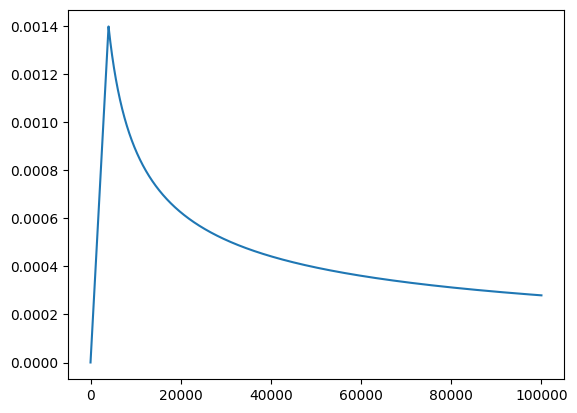
The realization of learning rate scheduling is shown in the code block below.
def get_rate(d_model, step_num, warmup_step):
# lr = 0.001
lr = d_model**(-0.5) * min(step_num**(-0.5), step_num*warmup_step**(-1.5))
return lr
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
@property
def param_groups(self):
return self.optimizer.param_groups
def multiply_grads(self, c):
"""Multiplies grads by a constant *c*."""
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.data.mul_(c)
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return 0 if not step else self.factor * get_rate(self.model_size, step, self.warmup)
Label Smoothing regularization is also employed in our program to help avoid overfitting. As shown in the figure below, when calculating loss, Label Smoothing Regularization lets the model learn to generate less concentrated distribution, and prevent over-confidence. As occasionally the ground truth may not be the only answer, thus, when calculating loss, we reserve some probability for incorrect labels, and this can help to avoid overfitting.
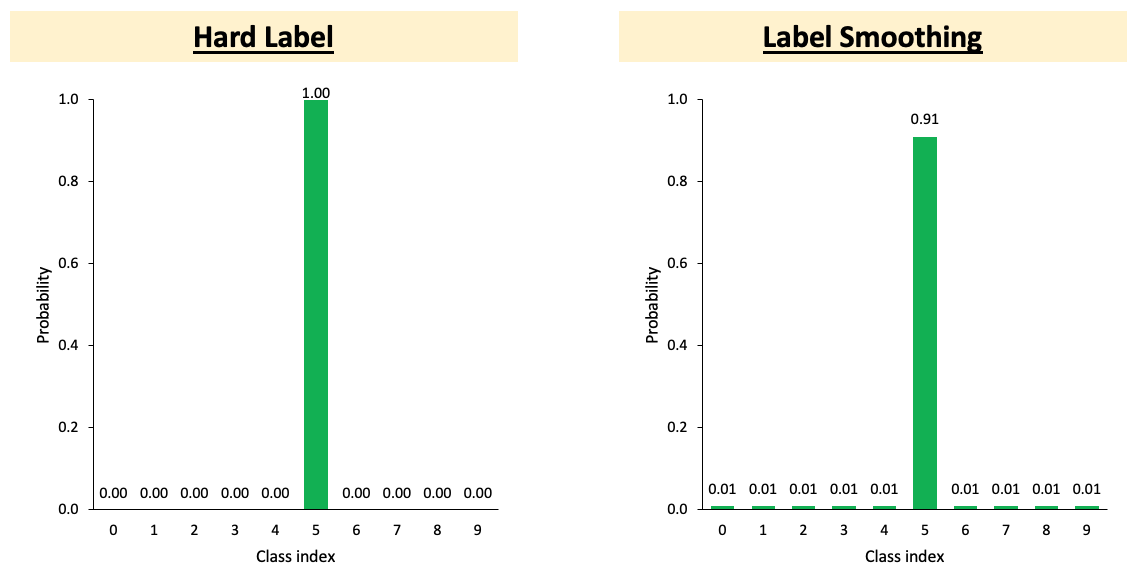
The realization of Label Smoothing regularization (reference) is shown in the code block below.
class LabelSmoothedCrossEntropyCriterion(nn.Module):
def __init__(self, smoothing, ignore_index=None, reduce=True):
super().__init__()
self.smoothing = smoothing
self.ignore_index = ignore_index
self.reduce = reduce
def forward(self, lprobs, target):
if target.dim() == lprobs.dim() - 1:
target = target.unsqueeze(-1)
# nll: Negative log likelihood,the cross-entropy when target is one-hot. following line is same as F.nll_loss
nll_loss = -lprobs.gather(dim=-1, index=target)
# reserve some probability for other labels. thus when calculating cross-entropy,
# equivalent to summing the log probs of all labels
smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
if self.ignore_index is not None:
pad_mask = target.eq(self.ignore_index)
nll_loss.masked_fill_(pad_mask, 0.0)
smooth_loss.masked_fill_(pad_mask, 0.0)
else:
nll_loss = nll_loss.squeeze(-1)
smooth_loss = smooth_loss.squeeze(-1)
if self.reduce:
nll_loss = nll_loss.sum()
smooth_loss = smooth_loss.sum()
# when calculating cross-entropy, add the loss of other labels
eps_i = self.smoothing / lprobs.size(-1)
loss = (1.0 - self.smoothing) * nll_loss + eps_i * smooth_loss
return loss
criterion = LabelSmoothedCrossEntropyCriterion(
smoothing=0.1, # generally, 0.1 is good enough
ignore_index=task.target_dictionary.pad(),
)
3.4. Model training
The block below shows the code used to train the model for one epoch.
def train_one_epoch(epoch_itr, model, task, criterion, optimizer, accum_steps=1):
itr = epoch_itr.next_epoch_itr(shuffle=True)
itr = iterators.GroupedIterator(itr, accum_steps) # gradient accumulation: update every accum_steps samples
stats = {"loss": []}
scaler = GradScaler() # automatic mixed precision (amp)
model.train()
progress = tqdm.tqdm(itr, desc=f"train epoch {epoch_itr.epoch}", leave=False)
for samples in progress:
model.zero_grad()
accum_loss = 0
sample_size = 0
# gradient accumulation: update every accum_steps samples
for i, sample in enumerate(samples):
if i == 1:
# emptying the CUDA cache after the first step can reduce the chance of OOM
torch.cuda.empty_cache()
sample = utils.move_to_cuda(sample, device=device)
target = sample["target"]
sample_size_i = sample["ntokens"]
sample_size += sample_size_i
# mixed precision training
with autocast():
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1))
# logging
accum_loss += loss.item()
# back-prop
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
optimizer.multiply_grads(1 / (sample_size or 1.0)) # (sample_size or 1.0) handles the case of a zero gradient
gnorm = nn.utils.clip_grad_norm_(model.parameters(), config.clip_norm) # grad norm clipping prevents gradient exploding
scaler.step(optimizer)
scaler.update()
# logging
loss_print = accum_loss/sample_size
stats["loss"].append(loss_print)
progress.set_postfix(loss=loss_print)
if config.use_wandb:
wandb.log({
"train/loss": loss_print,
"train/grad_norm": gnorm.item(),
"train/lr": optimizer.rate(),
"train/sample_size": sample_size,
})
loss_print = np.mean(stats["loss"])
logger.info(f"training loss: {loss_print:.4f}")
return stats
Next, the code for validation is shown in the block below. To prevent overfitting, validation is required every epoch to validate the performance on unseen data. However, Validation loss alone cannot describe the actual performance of the model. So we will directly produce translation hypotheses based on current model, then calculate BLEU score with the reference translation.
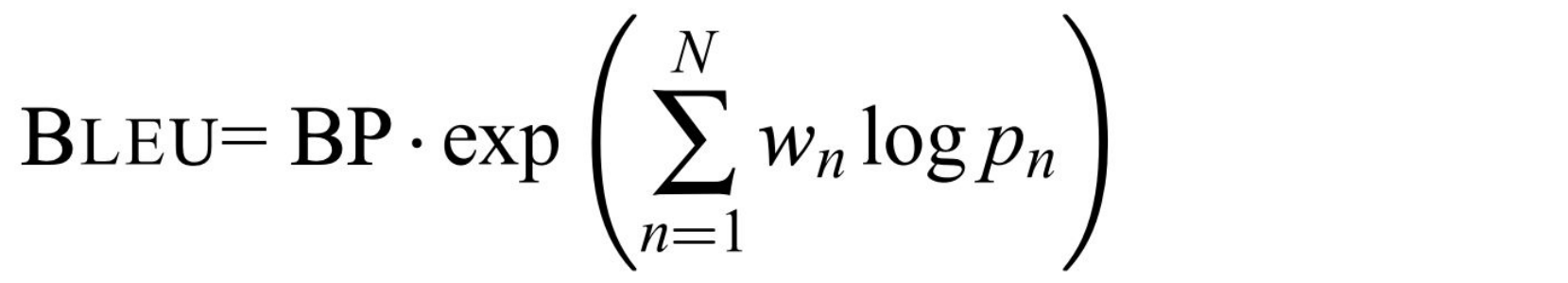
In the equation above, BP is brevity penalty, w_n is weight, and p_n is n-gram precision. Essentially, BLEU score measures the similarity between the output and target. Due to high variance, empirically we will train the model for more epochs to stabilize the results. In our project, we will use fairseq’s sequence generator for beam search to generate translation hypotheses. Fairseq’s beam search generator, given model and input sequence, will produce translation hypotheses by beam search.
def validate(model, task, criterion, log_to_wandb=True):
logger.info('begin validation')
itr = load_data_iterator(task, "valid", 1, config.max_tokens, config.num_workers).next_epoch_itr(shuffle=False)
stats = {"loss":[], "bleu": 0, "srcs":[], "hyps":[], "refs":[]}
srcs = []
hyps = []
refs = []
model.eval()
progress = tqdm.tqdm(itr, desc=f"validation", leave=False)
with torch.no_grad():
for i, sample in enumerate(progress):
# validation loss
sample = utils.move_to_cuda(sample, device=device)
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
target = sample["target"]
sample_size = sample["ntokens"]
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1)) / sample_size
progress.set_postfix(valid_loss=loss.item())
stats["loss"].append(loss)
# do inference
s, h, r = inference_step(sample, model)
srcs.extend(s)
hyps.extend(h)
refs.extend(r)
tok = 'zh' if task.cfg.target_lang == 'zh' else '13a'
stats["loss"] = torch.stack(stats["loss"]).mean().item()
stats["bleu"] = sacrebleu.corpus_bleu(hyps, [refs], tokenize=tok) # Compute BLEU score
stats["srcs"] = srcs
stats["hyps"] = hyps
stats["refs"] = refs
if config.use_wandb and log_to_wandb:
wandb.log({
"valid/loss": stats["loss"],
"valid/bleu": stats["bleu"].score,
}, commit=False)
showid = np.random.randint(len(hyps))
logger.info("example source: " + srcs[showid])
logger.info("example hypothesis: " + hyps[showid])
logger.info("example reference: " + refs[showid])
# show bleu results
logger.info(f"validation loss:\t{stats['loss']:.4f}")
logger.info(stats["bleu"].format())
return stats
Finally, we are ready to train the model, and here is the code to do that.
epoch_itr = load_data_iterator(task, "train", config.start_epoch, config.max_tokens, config.num_workers)
try_load_checkpoint(model, optimizer, name=config.resume)
while epoch_itr.next_epoch_idx <= config.max_epoch:
# train for one epoch
train_one_epoch(epoch_itr, model, task, criterion, optimizer, config.accum_steps)
stats = validate_and_save(model, task, criterion, optimizer, epoch=epoch_itr.epoch)
logger.info("end of epoch {}".format(epoch_itr.epoch))
epoch_itr = load_data_iterator(task, "train", epoch_itr.next_epoch_idx, config.max_tokens, config.num_workers)
Since we employed wandb package in our code, it will enable us to log the loss, bleu, etc. in the training process as well as to visualize them.
logging.basicConfig(
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level="INFO", # "DEBUG" "WARNING" "ERROR"
stream=sys.stdout,
)
proj = "P8.seq2seq"
logger = logging.getLogger(proj)
if config.use_wandb:
import wandb
wandb.init(project=proj, name=Path(config.savedir).stem, config=config)

The training loss and validation loss is shown in the figure below. From this figure, we can see that after more than 35,000 steps, both the training loss and validation loss are stabilized. Also we noticed that there is very little overfitting in our model, because the training loss and validation loss are very close to each other.
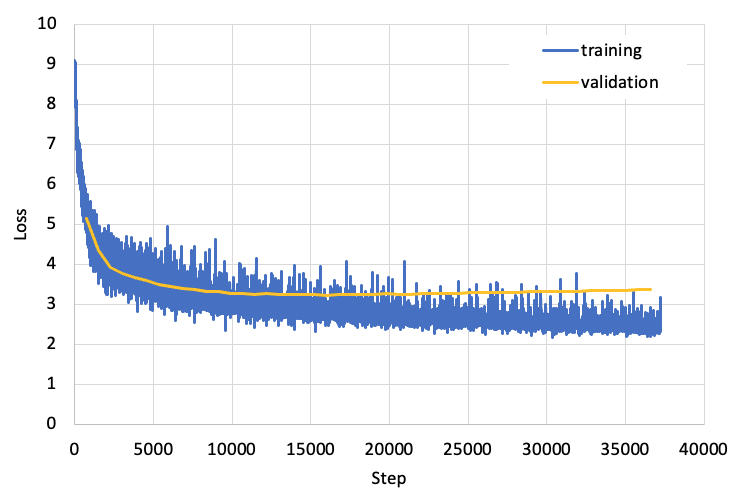
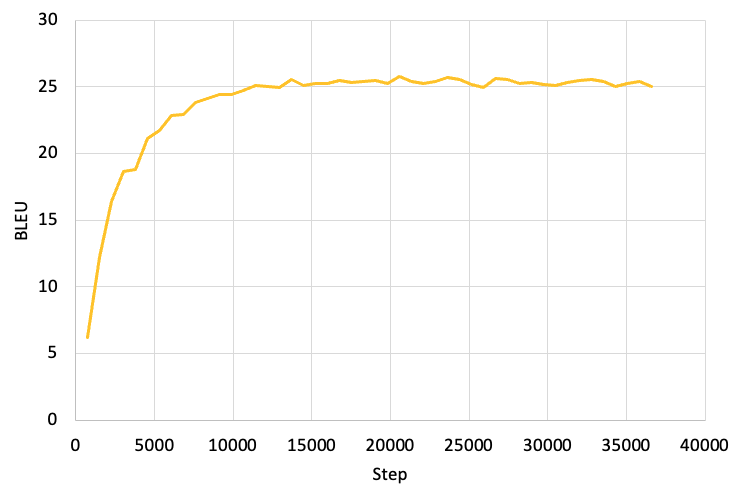
Next we will examine the BLEU score of the validation set, and the results are shown in the figure below. From this figure, we can see that after about 12,000 steps, out BLEU score exceeds 25, and the maximum BLEU score is 25.78.
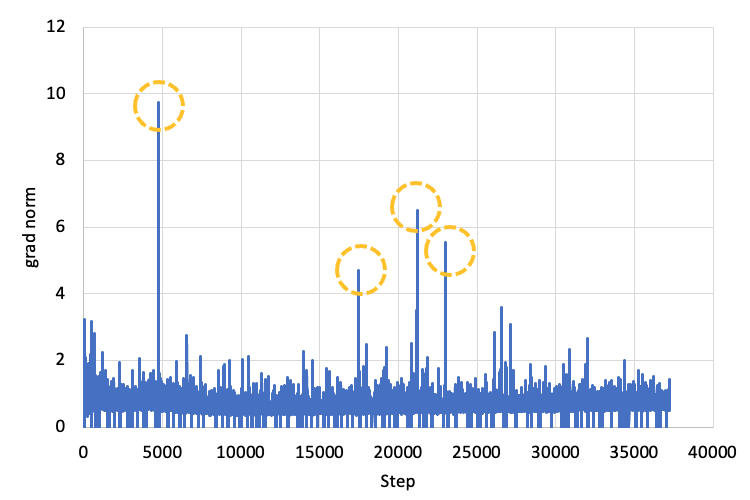
One famous difficulty in training neural networks is exploding gradient (ref). To address this issue, in our code we will first set up a maximum norm value max_norm. Then we will collect the gradient of each parameters to be a vector and calculate the p-norm of the vector and call it Lnorm. If Lnorm > max_norm, then we will calculate the scale factor scale_factor = max_norm / Lnorm and multiply each gradient by the scale factor. The gradient norm vs step is shown in the figure below, with large gradient norm (and gradient norm clipping) marked by orange circle.
Finally, we will examine some English-Chinese translation results manually. During the training process, we will save the translation results of validation set at the end of each epoch. Here we arbitraly choose record #17561 and compare the translation results after different epoches. From the results shown below, we can find that we train the model for more epoches, the quality of translation gets better and better, and this improvement is particular noticable in the first 16 epoches. In addition, all the data are available at Google Drive.
Source langauge: what you see here is two male chimpanzees who are the same size , but one is walking upright , has his hair up , has a big rock in his hand , and he's the alpha male .
Translation after epoch 1 (samples1.en-zh.txt): 你看到這兩個小小小的小小小 , 但他走走了一半 , 但他走走了他 , 但他走進步 。
Translation after epoch 2 (samples2.en-zh.txt): 這裡你看到的是兩個兩個大猩猩 , 其中一個是大小的大小 , 但他在他的手中 , 他的大大大大大大大小 , 牠的大大小 , 大大大大大小 。
Translation after epoch 4 (samples4.en-zh.txt): 這裡有兩個男性黑猩猩是相同的 , 但一個是同一個 , 他的頭髮有他的頭髮 , 他是雄性領袖 , 他是雄性領袖 。
Translation after epoch 8 (samples8.en-zh.txt): 這裡你看到的是兩隻雄猩猩猩 , 牠們的身高相同大小 , 但一隻是直立行走的 , 牠的頭髮上有一隻大石頭 , 手上有一隻大石頭 , 牠是雄性領袖 。
Translation after epoch 12 (samples12.en-zh.txt): 各位現在看到的是兩隻雄性黑猩猩 , 大小相同 , 但其中一隻是直立行走的 , 手上有一顆大石頭 , 牠是雄性領袖 。
Translation after epoch 16 (samples16.en-zh.txt): 這裡你看到的是兩隻雄性黑猩猩 , 大小相同 , 但一隻是直立行走 , 牠的頭髮有頭髮 , 手上有一塊巨大的石頭 , 他是雄性領袖 。
Translation after epoch 24 (samples24.en-zh.txt): 這裡你看到的是兩隻雄性黑猩猩 , 大小相同 , 但有一隻直立行走 , 牠的頭髮長起來 , 手上有很大的石頭 , 牠是雄性領袖 。
Translation after epoch 32 (samples32.en-zh.txt): 各位在這裡看到的是兩隻雄猩猩 , 大小相同 , 但一隻正在走向直上 , 牠的頭髮舉起來 , 手上有很大的石頭 , 而牠是雄性領袖 。
Translation after epoch 40 (samples40.en-zh.txt): 這裡你可以看到兩隻雄猩猩 , 大小相同 , 但一隻正在直立行走 , 牠的頭髮長高 , 牠的手也有很大的石頭 , 而牠是雄性領袖 。
Translation after epoch 48 (samples48.en-zh.txt): 各位現在看到的是兩隻雄猩猩 , 大小相同 , 但一隻正在直立行走 , 牠頭髮向上 , 牠手上有很大的石頭 , 牠是雄性領袖 。
4. Conclusions
In this project, we built a Transformer-based model for English-Chinese translation. The model was trained on the TED2020 En-Zh Bilingual Parallel Corpus, and we achieve BLEU score of 25.78 on the validation set. We have also examined some translation results manually and found that the model developed in this work can indeed generate high quality translations. In the future, we would like to employ back translation in our model so that the tanslation results will be more natual and of even higher quality.