Project 9: Generative QA with Retrieval-Augmented Generation (RAG) and TruEra Evaluation
1. Overview
In this project, we will build a Generative Question Answering model with Retrieval-Augmented Generation (RAG) with the help of LlamaIndex that can answer questions from internal documentation. We will also evaluate, iterate, and improve the model by using TruLens.
The Python Notebook containing the complete model development process and the data used in this project can be found at Google Drive.
2. Retrieval-Augmented Generation (RAG) for Question Answering (QA)
In the first part of this section, we will discuss the basic RAG pipeline for generative Question Answering from internal documentation. Then in the following parts, we will discuss two advanced RAG pipelines, including Sentence-Window Retrieval and Auto-Merging Retrieval.
2.1. Basic RAG Pipeline
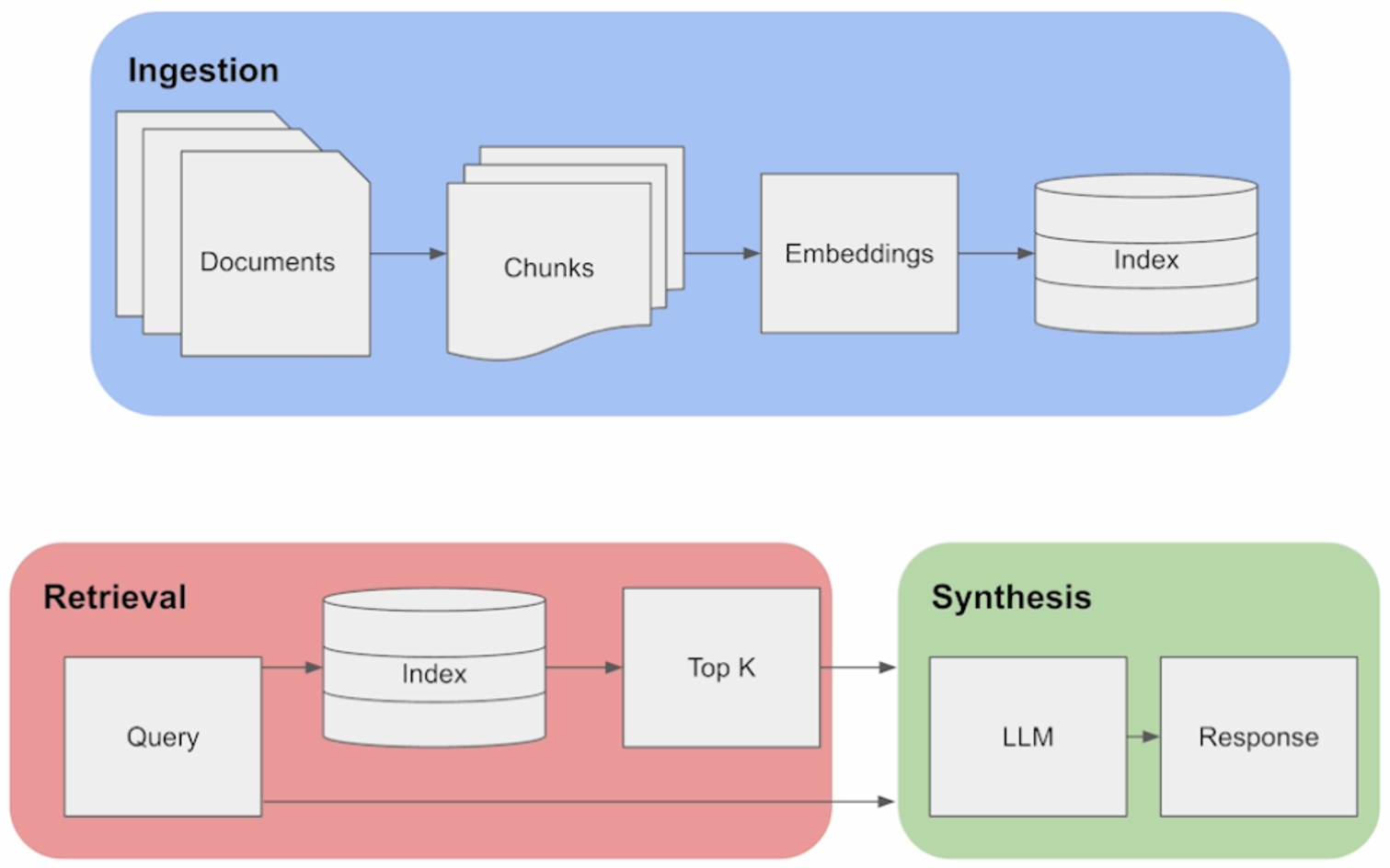
The structure of a basic Retrieval Augmented Generation (RAG) pipeline for Generative Question Answering (QA) is shown above. Generally, it consists of three different components, Ingestion, Retrieval, and Synthesis.
In the Ingestion phase, we first load in a set of documents. For each document, we split it into a set of text chunks using a text splitter. Then for each chunk, we generate an embedding for that chunk using an embedding model. And then for each chunk with embedding, we offload it to an index. Once the data is stored within an index, we then perform retrieval against that index. First, we launch a user query against the index, and then we fetch the top K most similar chunks to the user query. Afterwards, we take these relevant chunks, combine it with the user query, and put it into the prompt window of the LLM in the synthesis phase. And this allows us to generate a final response.
2.2. Sentence-Window Retrieval
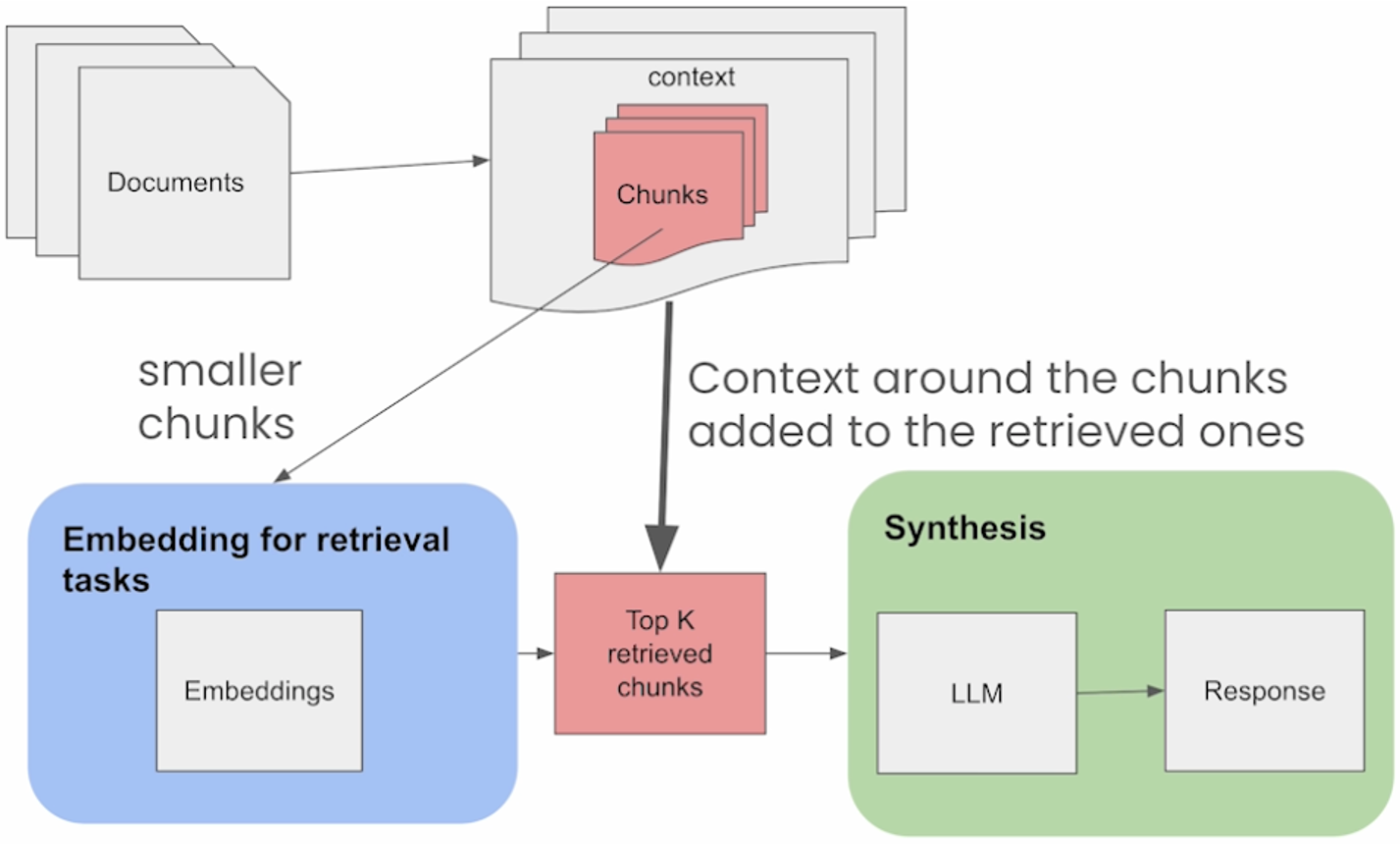
The advanced technique of Sentence-Window Retrieval is illustrated in the figure above. Similar to the basic RAG Pipeline, Sentence-Window Retrieval also works by embedding and retrieving single sentences, i.e., more granular chunks. But after retrieval, the sentences are replaced with a larger window of sentences around the original retrieved sentence. The intuition is that this allows for the LLM in the Synthesis phase to have more context for the information retrieved in order to better answer queries while still retrieving on more granular pieces of information. Consequently, it can improve both retrieval as well as synthesis performance.
In practice, we will gradually increase the sentence window size starting with 1, evaluate the model performance with TruLens and the RAG triad (will be discussed in the next section), track experiments to pick the best sentence window size. As we go through this exercise, we also need to note the trade-offs between token usage or cost. As we increase the window size, the token usage and cost will go up, as in many cases will context relevance.
There is also a very interesting relationship between context relevance and Groundedness that you can see in practice. When context relevance is low, Groundedness tends to be low as well. This is because the LLM will usually try to fill in the gaps in the retrieved pieces of context by leveraging its knowledge from the pre-training stage. This results in a reduction in Groundedness, even if the answers actually happen to be quite relevant. As context relevance increases, Groundedness also tends to increase up to a certain point. But if the context size becomes too big, even if the context relevance is high, there could be a drop in the Groundedness because the LLM can get overwhelmed with contexts that are too large and fall back on its pre-existing knowledge base from the training phase.
2.3. Auto-Merging Retrieval
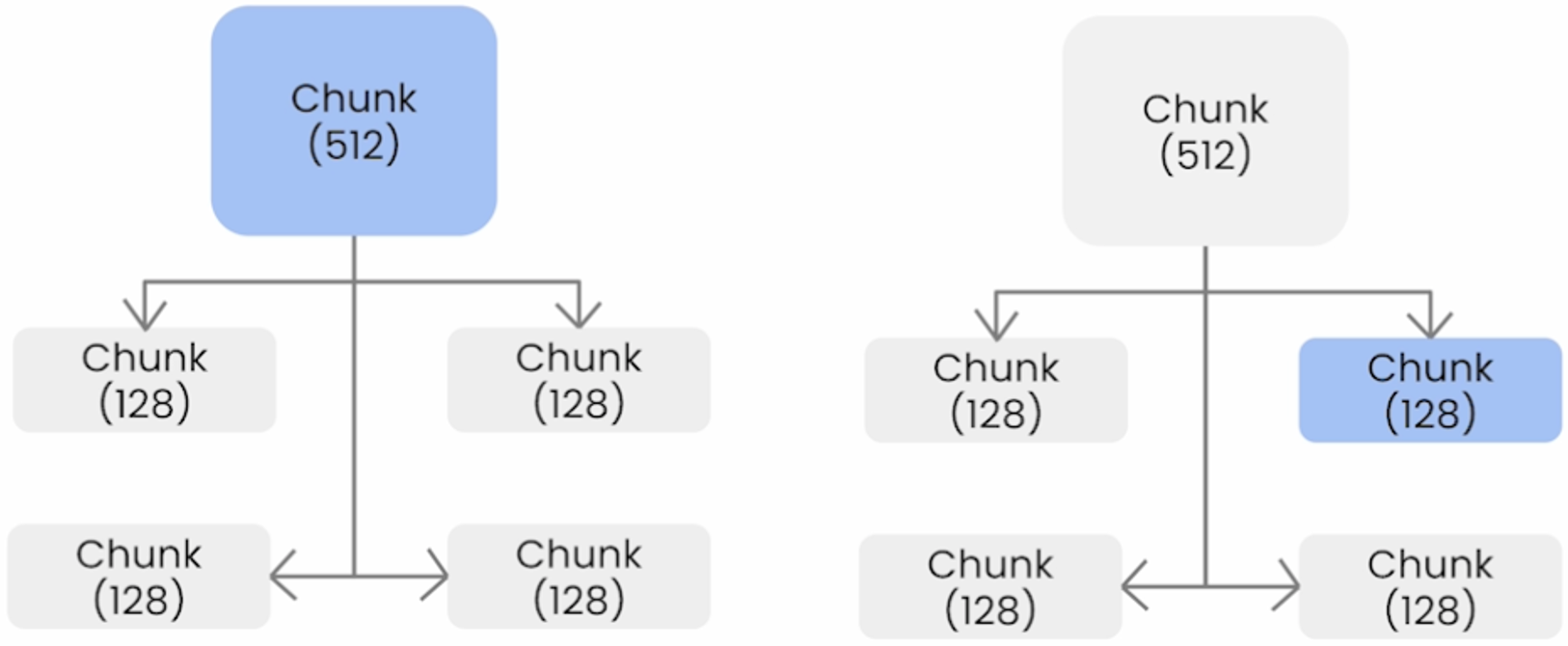
The next advanced retrieval technique we will discuss about is the Auto-Merging Retriever. In this approach, we will construct a hierarchy of larger parent nodes with smaller child nodes that reference the parent node, and the combination of all the child nodes is the same text as the parent node. For instance, as shown in the figure above, we might have a parent node of chunk size 512 tokens, and underneath there are four child nodes of chunk size 128 tokens that link to this parent node. The auto-merging retriever works by merging retrieved nodes into larger parent nodes, which means that during retrieval, if a parent actually has a majority of its children nodes retrieved, then we’ll replace the children nodes with the parent node.
Compared with the Auto-Merging Retrieval, a common issue with the basic RAG pipeline is that it retrieves a bunch of fragmented context chunks for the downstream Synthesis LLM, and this fragmentation issue may get worse as the chunk size becomes smaller. For instance, we might get back two or more retrieved context chunks in roughly the same section, but there’s actually no guarantees on the ordering of these chunks. This can potentially damage the LLM’s ability to synthesize over this retrieved context within its context window, because the order of text is usually quite important.
To set up auto-merging retriever, the first step is to define a hierarchical node parser. This means that nodes are parsed in decreasing sizes and contain relationships to their parent node. The next step is to construct the index, i.e., a vector index on each leaf node. All other intermediate and parent nodes are stored in a doc store and are retrieved dynamically during retrieval. During Retrieval we will fetch the top-K embeddings of the leaf nodes. If a majority of children nodes are retrieved for a given parent, they are swapped out for the parent instead by the auto-merging retriever.
In order for this merging to work well, we typically set a large top-K for the leaf nodes. Then in order to reduce token usage, we usually apply a re-ranker, e.g., sentence transformer re-rank module, after the merging has taken place. Finally, we will combine both the auto-merging retriever and the re-rank module into the retriever query engine, which handles both retrieval and synthesis.
3. RAG Triad of Metrics and TruEra
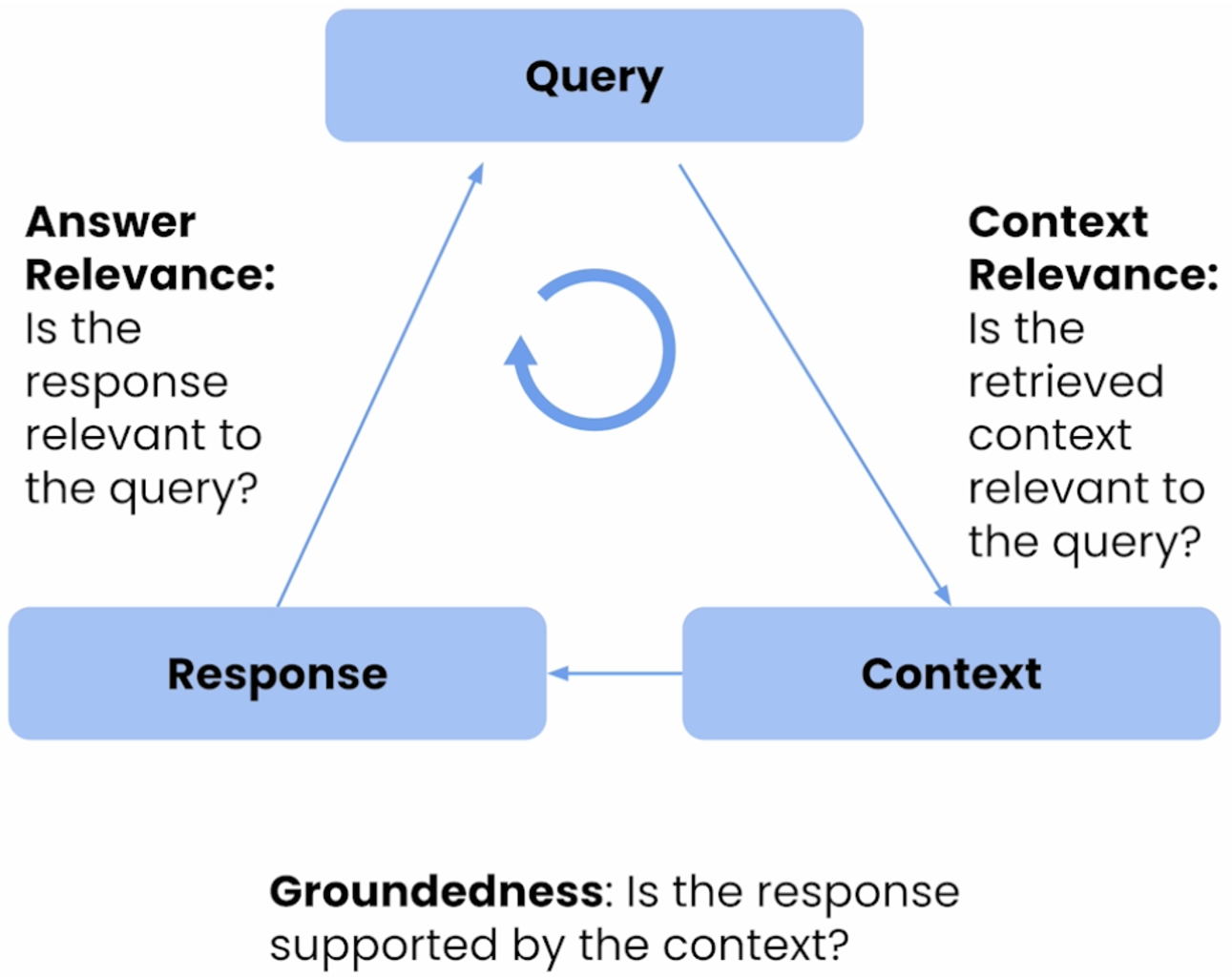
TruEra provides measurements of three key metrics for RAG applications.
-
The first one is Context Relevance, which answers the question of whether the retrieved context is relevant to the query, or how good is the retrieval?
-
The second one is Groundedness, which answers the question of whether the response is supported by the context, or how severe are the hallucinations in LLM?
-
The third one is Answer Relevance, which answers the question of whether the response is relevant to the query, or how useful is the final response?
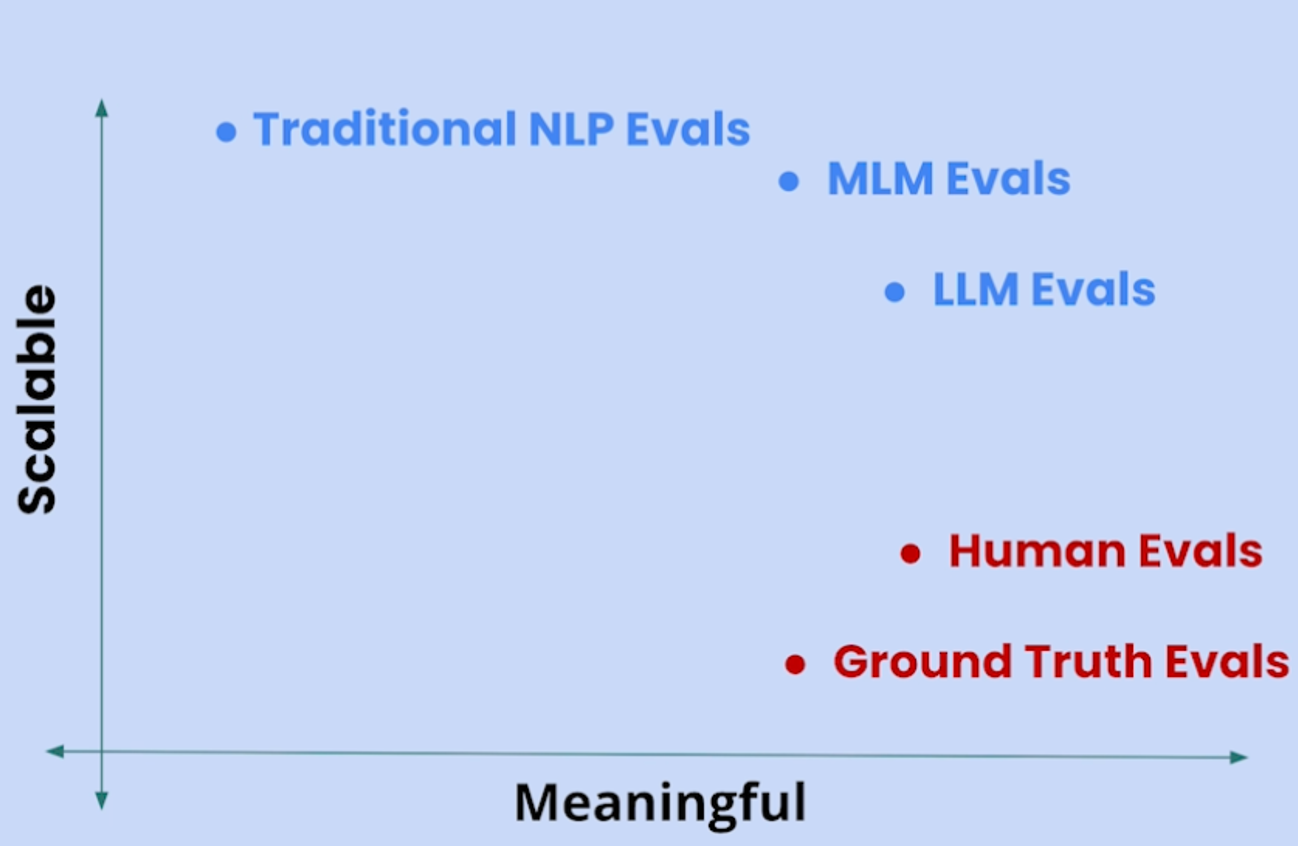
If we take a broad view of evaluation methods and plot them as a function of Meaningful and Scalable, we can get the figure above. From this figure, we can observe that Human evaluations and Ground truth evaluations are generally very meaningful but less scalable. On the other hand, Traditional NLP evaluations (e.g., BLEU and ROUGE), Medium size Language Mode (MLM) evaluations (e.g., BERT) are highly scalable but less meaningful. Among all these approaches, the Large size Language Mode (LLM) evaluations (e.g., GPT-4) are highly attractive, because it is both highly scalable and highly meaningful.
TruLens developed by TruEra provides feedback functions of Context Relevance, Groundedness, and Answer Relevance based on state-of-the-art LLMs such as OpenAI GPT-4. After reviewing the app’s inputs, outputs, and intermediate results, TruLens will provide a score and corresponding supporting evidence/chain-of-thought reasoning. This is particularly helpful in diagnosing the model, determining its failure mode, and optimizing the model settings.
4. Model development
4.1. Data Pre-Processing
The documents we will use in this study are 10 articles from L.L. Bean. These articles are very interesting and teach people with some very useful knowledge. Here are the links to these articles. We will first print each article as a PDF file, and then we will clean them up and combine them together into a single file named Outdoor-Basics.pdf.
In addition, we have also prepared 10 questions below and put them in a file called eval_questions_outdoor.txt.
-
What essential gear do I need for a basic camping trip?
-
Which three types fuel do I need to burn a successful campfire?
-
What are All-Mountain Wide Skis best for?
-
What are Cross-Country Mountain Bikes?
-
What are the three key considerations in choosing a base layer?
-
How to focus binoculars?
-
What are Energy Gels?
-
What are the three variations of altitude illnesses?
-
What are the four building blocks of Marathon training?
-
What are tips for Ultralight Backpacking?
-
What are the causes of altitude sickness?
We will ask our RAG QA model to answer these questions based on the articles above, and evaluate the model’s performance by TruLens.
4.2. Basic RAG Pipeline Model
To build the basic RAG Pipeline Model, we need to import the SimpleDirectoryReader from llama_index, and then read the internal document. The internal document will be read as a list of llama_index.schema.Document, and the length of the list equals to the number of pages in the document. Each llama_index.schema.Document object (i.e., each page) contains a unique Doc ID and text on that page.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./Outdoor-Basics.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])
####################### Output ##########################
# <class 'list'>
# 51
# <class 'llama_index.schema.Document'>
# Doc ID: c3dc0f74-5361-40c3-9baa-557864340972
# Text: Beginner's Guide to Your First Campout rei.com /learn/expert-
# advice/camping-for-beginners.html Here's what you should bring, wear
# and know for your first campout. Even if you’re the most urban of
# creatures, the urge to get out of the city—to camp out, in fact—can
# seize your imagination at any time. If you find yourself contemplating
# car camping ...
With the help of LlamaIndex, building the basic RAG Pipeline Model becomes very straightforward, as shown in the code snippet below.
from llama_index import Document
from llama_index import VectorStoreIndex
from llama_index import ServiceContext
from llama_index.llms import OpenAI
document = Document(text="\n\n".join([doc.text for doc in documents]))
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-large-en-v1.5")
index = VectorStoreIndex.from_documents([document],service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query("What are the four building blocks of Marathon training?")
print(str(response))
####################### Output ##########################
# The four building blocks of marathon training are base mileage, the long run, speed work, and rest and recovery.
To evaluate the model performance using TruLens, we can employ the following code snippet.
from trulens_eval import Tru
from utils import get_prebuilt_trulens_recorder
tru = Tru()
tru.reset_database()
tru_recorder = get_prebuilt_trulens_recorder(query_engine, app_id="Direct Query Engine")
with tru_recorder as recording:
for question in eval_questions:
response = query_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])
tru.run_dashboard()
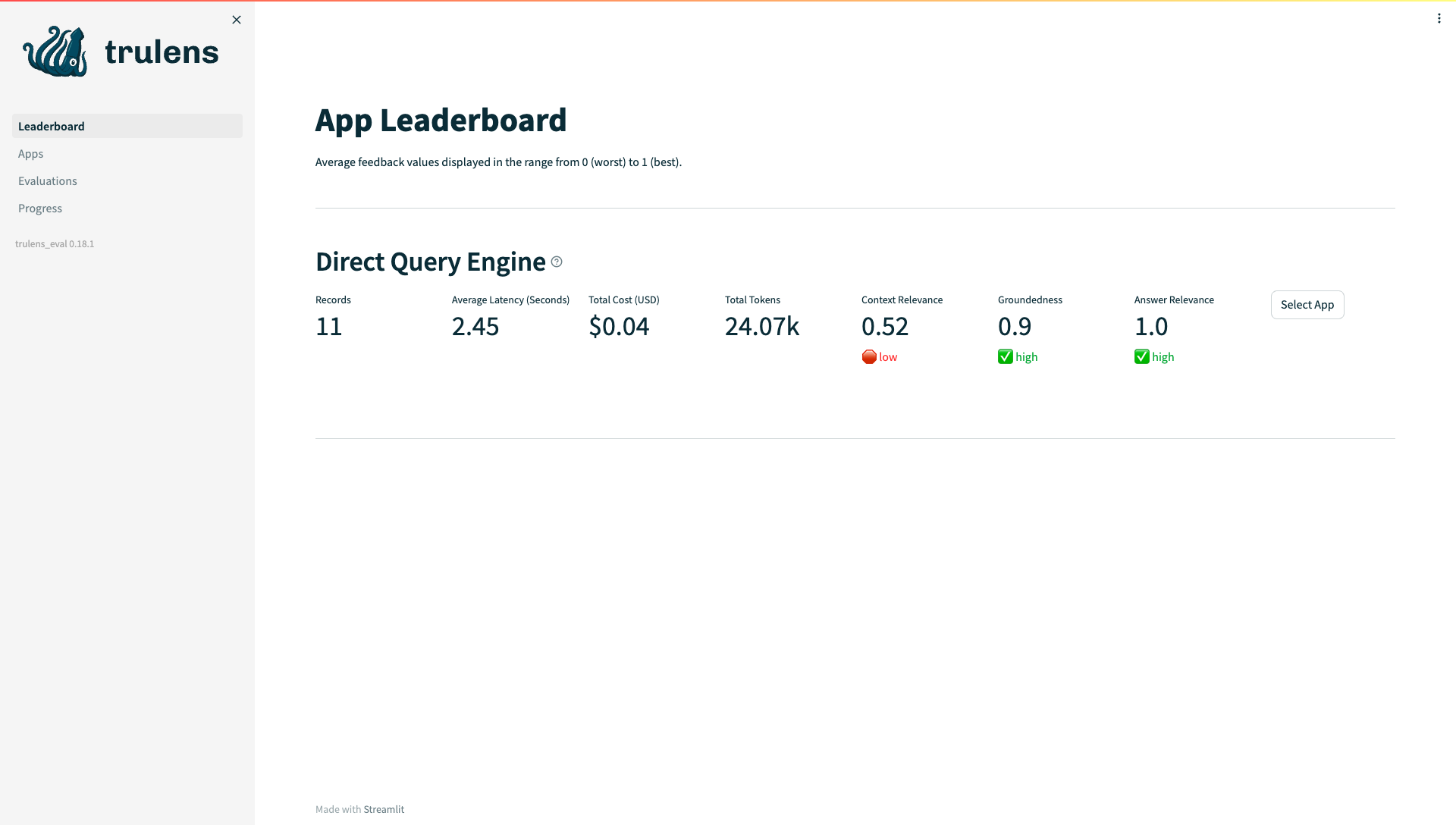
If we check the TruLens Dashboard, we can see that while the model has relatively lower score in Context Relevance, it has very high scores for the Groundedness and Answer Relevance.
4.3. Sentence-Window Retrieval Model
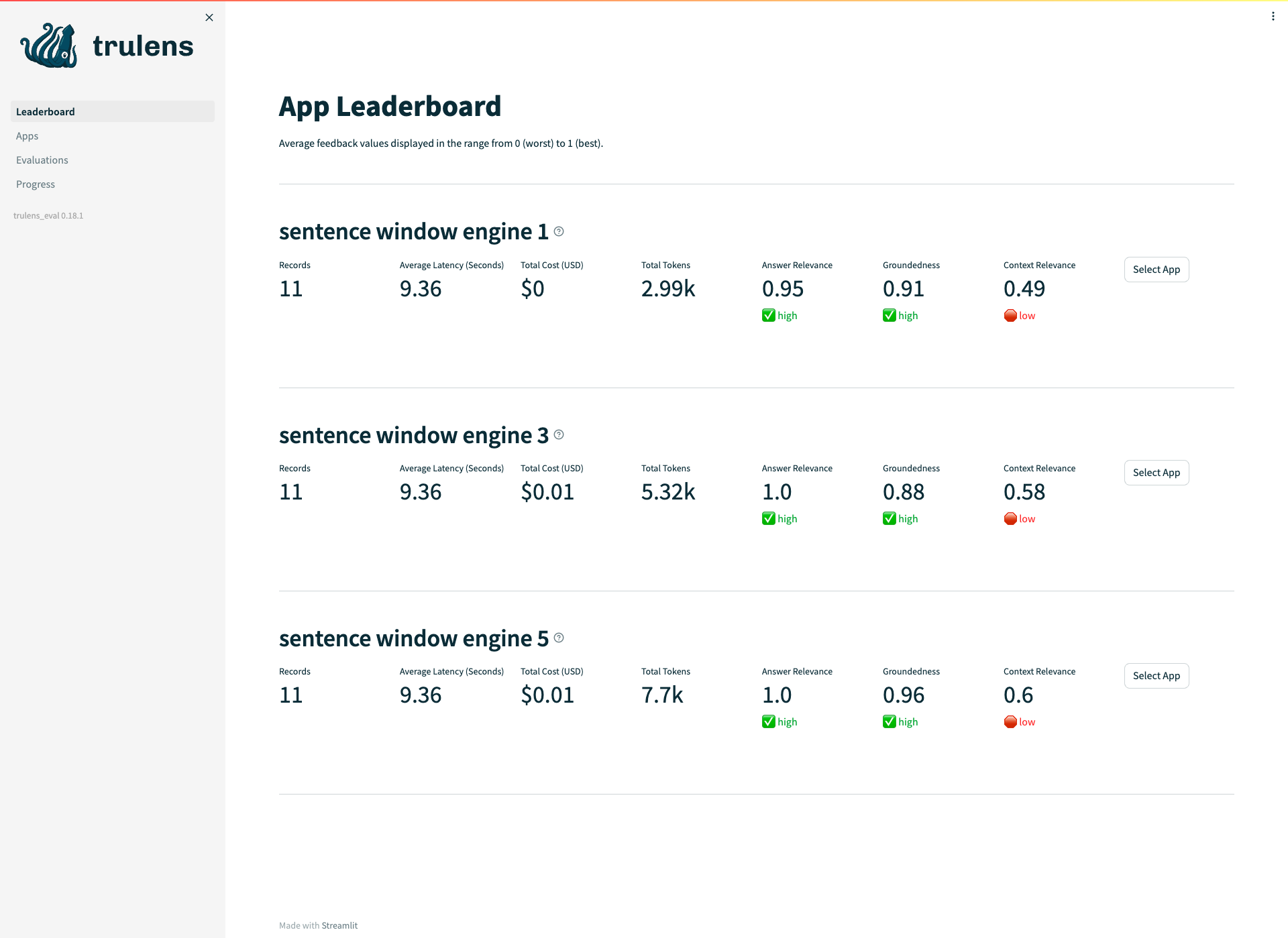
To employ the more advanced Sentence-Window Retrieval Model, we can update the Retrieve phase with the following code snippet. From the results shown below, we can observe that as the size of the Sentence-Window gets larger, all metrics, especially the Context Relevance, get improved significantly.
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.llms import OpenAI
from llama_index import ServiceContext
from llama_index import VectorStoreIndex
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.schema import NodeWithScore
from copy import deepcopy
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index import QueryBundle
from llama_index.schema import TextNode, NodeWithScore
# Window-sentence retrieval setup -- window_size = 5
node_parser_5 = SentenceWindowNodeParser.from_defaults(window_size=5, window_metadata_key="window", original_text_metadata_key="original_text",)
# Building the index
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
sentence_context_5 = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-large-en-v1.5", node_parser=node_parser_5,)
sentence_index_5 = VectorStoreIndex.from_documents([document], service_context=sentence_context_5)
sentence_index_5.storage_context.persist(persist_dir="./sentence_index_5")
# Building the postprocessor
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(top_n=2, model="BAAI/bge-reranker-large")
# Runing the query engine
sentence_window_engine_5 = sentence_index_5.as_query_engine(similarity_top_k=6, node_postprocessors=[postproc, rerank])
# TruLens Evaluation
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
print("Question: ", question)
with tru_recorder as recording:
response = query_engine.query(question)
Tru().reset_database()
tru_recorder_5 = get_prebuilt_trulens_recorder(sentence_window_engine_5, app_id='sentence window engine 5')
run_evals(eval_questions, tru_recorder_5, sentence_window_engine_5)
Tru().run_dashboard()
4.4. Auto-merging Retrieval Model
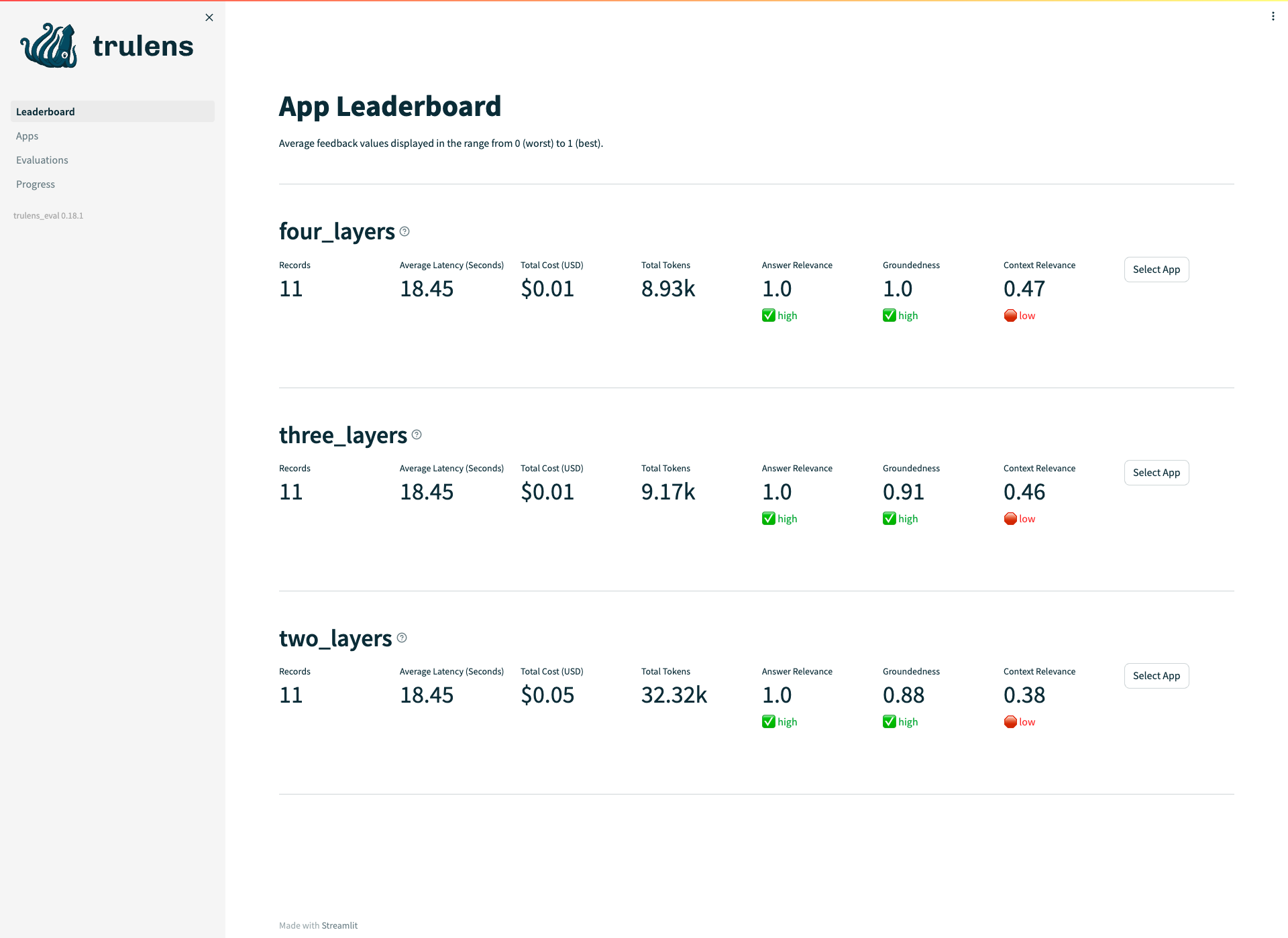
Next, we will continue to employ another advanced retrieval model, i.e., the Auto-merging Retrieval Model, by employing the code snippets below. Similarly, we can see that as by introducing and finetuning the Auto-merging Retrieval Model, all metrics get improved noticeably.
from llama_index.node_parser import HierarchicalNodeParser
from llama_index.node_parser import get_leaf_nodes
from llama_index.llms import OpenAI
from llama_index import ServiceContext
from llama_index import VectorStoreIndex, StorageContext
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.retrievers import AutoMergingRetriever
from llama_index.query_engine import RetrieverQueryEngine
from trulens_eval import Tru
from utils import get_prebuilt_trulens_recorder
node_parser_4 = HierarchicalNodeParser.from_defaults(chunk_sizes=[8192, 2048, 512, 128])
nodes_4 = node_parser_4.get_nodes_from_documents([document])
leaf_nodes_4 = get_leaf_nodes(nodes_4)
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
auto_merging_context_4 = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-large-en-v1.5",node_parser=node_parser_4,)
storage_context_4 = StorageContext.from_defaults()
storage_context_4.docstore.add_documents(nodes_4)
automerging_index_4 = VectorStoreIndex(leaf_nodes_4, storage_context=storage_context_4, service_context=auto_merging_context_4)
automerging_index_4.storage_context.persist(persist_dir="./merging_index_4")
automerging_retriever_4 = automerging_index_4.as_retriever(similarity_top_k=12)
retriever_4 = AutoMergingRetriever(automerging_retriever_4, automerging_index_4.storage_context, verbose=True)
rerank = SentenceTransformerRerank(top_n=6, model="BAAI/bge-reranker-base")
auto_merging_engine_4 = RetrieverQueryEngine.from_args(automerging_retriever_4, node_postprocessors=[rerank])
Tru().reset_database()
tru_recorder = get_prebuilt_trulens_recorder(auto_merging_engine_4, app_id ='four_layers')
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
print("Question: ", question)
with tru_recorder as recording:
response = query_engine.query(question)
run_evals(eval_questions, tru_recorder, auto_merging_engine_4)
Tru().run_dashboard()
5. Conclusions
In this project, we built a Generative QA model with RAG that can answer questions from internal documents by using LlamaIndex. The model performance, including Context Relevance, Groundedness, and Answer Relevance, are evaluated by TruLens developed by TruEra.
In addition to the basic RAG pipeline, we have also explored more advanced RAG pipeline models, including Sentence-Window Retrieval Model and Auto-merging Retrieval Model. The results indicate that more advanced RAG models will indeed lead to better model performance. By finetuning model parameters together with TruLens, we can effectively improve the model performance.
References:
Source of hero image: https://medium.com/geekculture/create-a-question-answer-service-using-gpt-3-and-openai-41498c73879b
Source of images in this post: https://learn.deeplearning.ai/building-evaluating-advanced-rag
- Natural Language Processing
- Generative Question Answering (QA)
- GPT
- Retrieval-Augmented Generation (RAG)
- TruEra